Preface
I like the language JS very much. I feel that it is the same as the C language. In the C language, many things need to be implemented by ourselves, so that we can exert unlimited creativity and imagination. In JS, although many things have been provided in V8, but with JS, you can still create a lot of interesting things, as well as interesting writing methods.
In addition, JS should be the only language I have seen that does not implement network and file functions. Network and files are a very important ability, and for programmers, they are also very core and basic knowledge. Fortunately, Node.js was created. On the basis of JS, Node.js uses the capabilities provided by V8 and Libuv, which greatly expands and enriches the capabilities of JS, especially the network and files, so that I can not only use JS, you can also use functions such as network and files, which is one of the reasons why I gradually turned to Node.js, and one of the reasons why I started to study the source code of Node.js.
Although Node.js satisfies my preferences and technical needs, at the beginning, I did not devote myself to code research, but occasionally looked at the implementation of some modules. The real beginning was to do "Node.js". .js is how to use Libuv to implement event loop and asynchrony”. Since then, most of my spare time and energy have been devoted to source code research.
I started with Libuv first, because Libuv is one of the core of Node.js. Since I have studied some Linux source code, and I have been learning some principles and implementations of the operating system, I did not encounter much difficulty when reading Libuv. The use and principles of C language functions can basically be understood. , the point is that each logic needs to be clearly defined.
The methods I use are annotations and drawings, and I personally prefer to write annotations. Although code is the best comment, I am willing to take the time to explain the background and meaning of the code with comments, and comments will make most people understand the meaning of the code faster. When I read Libuv, I also read some JS and C++ code interspersed.
The way I read Node.js source code is, pick a module and analyze it vertically from the JS layer to the C++ layer, then to the Libuv layer.
After reading Libuv, the next step is to read the code of the JS layer. Although JS is easy to understand, there is a lot of code in the JS layer, and I feel that the logic is very confusing, so so far, I still have not read it carefully. follow-up plans.
In Node.js, C++ is the glue layer. In many cases, C++ is not used, and it does not affect the reading of Node.js source code, because C++ is often only a function of transparent transmission. It sends the request of the JS layer through V8, passed to Libuv, and then in reverse, so I read the C++ layer at the end.
I think the C++ layer is the most difficult. At this time, I have to start reading the source code of V8 again. It is very difficult to understand V8. I chose almost the earliest version 0.1.5, and then combined with the 8.x version. Through the early version, first learn the general principles of V8 and some early implementation details. Because the subsequent versions have changed a lot, but more of them are enhancements and optimizations of functions, and many core concepts have not changed. Lost direction and lost momentum.
However, even in the early version, many contents are still very complicated. The reason for combining the new version is because some functions were not implemented in the previous version. To understand its principle at this time, you can only look at the code of the new version and have the experience of the early version, reading the new version of the code also has certain benefits, and also know some reading skills to some extent.
Most of the code in Node.js is in the C++ and JS layers, so I am still reading the code of these two layers constantly. Or according to the vertical analysis of modules. Reading Node.js code gave me a better understanding of the principles of Node.js and a better understanding of JS. However, the amount of code is very large and requires a steady stream of time and energy investment. But when it comes to technology, it’s a wonderful feeling to know what it is, and it’s not a good feeling that you make a living off a technology but don’t know much about it.
Although reading the source code will not bring you immediate and rapid benefits, there are several benefits that are inevitable. The first is that it will determine your height, and the second is that when you write the code, youInstead of seeing some cold, lifeless characters. This may be a bit exaggerated, but you understand the principles of technology, and when you use technology, you will indeed have different experiences, and your thinking will also have more changes.
The third is to improve your learning ability. When you have more understanding and understanding of the underlying principles, you will learn more quickly when you are learning other technologies. For example, if you understand the principle of epoll, then you can see When Nginx, Redis, Libuv and other source code are used, the event-driven logic can basically be understood very quickly.
I am very happy to have these experiences, and I have invested a lot of time and energy. I hope to have more understanding and understanding of Node.js in the future, and I hope to have more practice in the direction of Node.js.
The purpose of this book
The original intention of reading the Node.js source code is to give yourself a deep understanding of the principles of Node.js, but I found that many students are also very interested in the principles of Node.js, because they have been writing about the principles of Node.js in their spare time.
Node.js source code analysis articles (based on Node.js V10 and V14), so I plan to organize these contents into a systematic book, so that interested students can systematically understand and understand the principles of Node.js. However, I hope that readers will not only learn the knowledge of Node.js from the book, but also learn how to read the source code of Node.js, and can complete the research of the source code independently. I also hope that more students will share their experiences. This book is not the whole of Node.js, but try to talk about it as much as possible.
The source code is very many, intricate, and there may be inaccuracies in understanding. Welcome to exchange. Because I have seen some implementations of early Linux kernels (0.11 and 1.2.13) and early V8 (0.1.5), the article will cite some of the codes in order to let readers know more about the general implementation principle of a knowledge point. If you are interested, you can read the relevant code by yourself.
The structure of the book
This book is divided into twenty-two chapters, and the code explained is based on the Linux system.
-
Mainly introduces the composition and overall working principle of Node.js, and analyzes the process of starting Node.js. Finally, it introduces the evolution of the server architecture and the selected architecture of Node.js.
-
It mainly introduces the basic data structure and general logic in Node.js, which will be used in later chapters.
-
Mainly introduces the event loop of Libuv, which is the core of Node.js. This chapter specifically introduces the implementation of each stage in the event loop.
-
Mainly analyze the implementation of thread pool in Libuv. Libuv thread pool is very important to Node.js. Many modules in Node.js need to use thread pool, including crypto, fs, dns, etc. Without a thread pool, the functionality of Node.js would be greatly reduced. At the same time, the communication mechanism between Libuv neutron thread and main thread is analyzed. It is also suitable for other child threads to communicate with the main thread.
-
Mainly analyze the implementation of flow in Libuv. Flow is used in many places in Node.js source code, which can be said to be a very core concept.
-
Mainly analyze some important modules and general logic of C++ layer in Node.js.
-
Mainly analyze the signal processing mechanism of Node.js. Signal is another way of inter-process communication.
-
Mainly analyze the implementation of the dns module of Node.js, including the use and principle of cares.
-
It mainly analyzes the implementation and use of the pipe module (Unix domain) in Node.js. The Unix domain is a way to realize inter-process communication, which solves the problem that processes without inheritance cannot communicate. And support for passing file descriptors greatly enhances the capabilities of Node.js.
-
Mainly analyze the implementation of timer module in Node.js. A timer is a powerful tool for timing tasks.
-
Mainly analyze the implementation of Node.js setImmediate and nextTick.
-
Mainly introduces the implementation of file modules in Node.js. File operations are functions that we often use.
-
Mainly introduces the implementation of the process module in Node.js. Multi-process enables Node.js to take advantage of multi-core capabilities.
-
Mainly introduces the implementation of thread module in Node.js. Multi-process and multi-thread have similar functions but there are some differences.
-
Mainly introduces the use and implementation principle of the cluster module in Node.js. The cluster module encapsulates the multi-process capability, making Node.j a server architecture that can use multi-process and utilize the multi-core capability.
-
Mainly analyze the implementation and related content of UDP in Node.js.
-
Mainly analyze the implementation of TCP module in Node.js. TCP is the core module of Node.js. Our commonly used HTTP and HTTPS are based on net module.
-
It mainly introduces the implementation of the HTTP module and some principles of the HTTP protocol.
-
Mainly analyze the principle of loading various modules in Node.js, and deeply understand what the require function of Node.js does.
-
Mainly introduce some methods to expand Node.js, use Node.js to expand Node.js.
-
It mainly introduces the implementation of JS layer Stream. The logic of the Stream module is very complicated, so I briefly explained it.
-
Mainly introduces the implementation of the event module in Node.js. Although the event module is simple, it is the core module of Node.js.
Readers This book is aimed at students who have some experience in using Node.js and are interested in the principles of Node.js, because this book analyzes the principles of Node.js from the perspective of Node.js source code, some of which are C, C++, so the reader needs to have a certain C and C++ foundation. In addition, it will be better to have a certain operating system, computer network, and V8 foundation.
Reading Suggestions
It is recommended to read the first few basic and general contents, then read the implementation of a single module, and finally, if you are interested, read the chapter on how to expand Node.js. If you are already familiar with Node.js and are just interested in a certain module or content, you can go directly to a certain chapter. When I first started to read the Node.js source code, I chose the V10.x version. Later, Node.js has been updated to V14, so some of the codes in the book are V10 and V14. Libuv is V1.23. You can get it on my github.
Source code reading
It is recommended that the source code of Node.js consists of JS, C++, and C.
-
Libuv is written in C language. In addition to understanding C syntax, understanding Libuv is more about the understanding of operating systems and networks. Some classic books can be referred to, such as "Unix Network Programming" 1 and 2 two volumes, "Linux System Programming Manual" upper and lower volumes, The Definitive Guide to TCP/IP, etc. There are also Linux API documentation and excellent articles on the Internet for reference.
-
C++ mainly uses the capabilities provided by V8 to expand JS, and some functions are implemented in C++. In general, C++ is more of a glue layer, using V8 as a bridge to connect Libuv and JS. I don't know C++, and it doesn't completely affect the reading of the source code, but it will be better to know C++. To read the C++ layer code, in addition to the syntax, you also need to have a certain understanding and understanding of the concept and use of V8.
-
JS code I believe that students who learn Node.js have no problem.
Node.js Composition and Principle
1.1 Introduction to Node.js
Node.js is an event-driven single-process single-threaded application. Single threading is embodied in Node.js maintaining a series of tasks in a single thread, and then In the event loop, the nodes in the task queue are continuously consumed, and new tasks are continuously generated, which continuously drives the execution of Node.js in the generation and consumption of tasks. From another point of view, Node.js can be said to be multi-threaded, because the bottom layer of Node.js also maintains a thread pool, which is mainly used to process some tasks such as file IO, DNS, and CPU computing.
Node.js is mainly composed of V8, Libuv, and some other third-party modules (cares asynchronous DNS parsing library, HTTP parser, HTTP2 parser, compression library, encryption and decryption library, etc.). The Node.js source code is divided into three layers, namely JS, C++, and C.
Libuv is written in C language. The C++ layer mainly provides the JS layer with the ability to interact with the bottom layer through V8. The C++ layer also implements some functions. The JS layer It is user-oriented and provides users with an interface to call the underlying layer.
1.1.1 JS Engine V8
Node.js is a JS runtime based on V8. It utilizes the capabilities provided by V8 and greatly expands the capabilities of JS. This extension does not add new language features to JS, but expands functional modules. For example, in the front end, we can use the Date function, but we cannot use the TCP function, because this function is not built-in in JS.
In Node.js, we can use TCP, which is what Node.js does, allowing users to use functions that do not exist in JS, such as files, networks. The core parts of Node.js are Libuv and V8. V8 is not only responsible for executing JS, but also supports custom extensions, realizing the ability of JS to call C++ and C++ to call JS.
For example, we can write a C++ module and call it in JS. Node.js makes use of this ability to expand the function. All C and C++ modules called by the JS layer are done through V8.
1.1.2 Libuv
Libuv is the underlying asynchronous IO library of Node.js, but it provides functions not only IO, but also processes, threads, signals, timers, inter-process communication, etc., and Libuv smoothes the differences between various operating systems. The functions provided by Libuv are roughly as follows • Full-featured event loop backed by epoll, kqueue, IOCP, event ports.
- Asynchronous TCP and UDP sockets
- Asynchronous DNS resolution
- Asynchronous file and file system operations
- File system events
- ANSI escape code controlled TTY
- IPC with socket sharing, using Unix domain sockets or named pipes (Windows)
- Child processes
- Thread pool
- Signal handling
- High resolution clock
- Threading and synchronization primitives
The implementation of Libuv is a classic producer-consumer model. In the entire life cycle of Libuv, each round of the cycle will process the task queue maintained by each phase, and then execute the callbacks of the nodes in the task queue one by one. In the callback, new tasks are continuously produced, thereby continuously driving Libuv.
The following is the overall execution process of Libuv

From the above figure, we roughly understand that Libuv is divided into several stages, and then continuously performs the tasks in each stage in a loop. Let's take a look at each stage in detail.
-
Update the current time. At the beginning of each event loop, Libuv will update the current time to the variable. The remaining operations of this cycle can use this variable to obtain the current time to avoid excessive Too many system calls affect performance, the additional effect is that the timing is not so precise. But in a round of event loop, Libuv will actively update this time when necessary. For example, when returning after blocking the timeout time in epoll, it will update the current time variable again.
-
If the event loop is in the alive state, start processing each stage of the event loop, otherwise exit the event loop.
What does alive state mean? If there are handles in the active and ref states, the request in the active state or the handle in the closing state, the event loop is considered to be alive (the details will be discussed later).
-
timer stage: determine which node in the minimum heap has timed out, execute its callback.
-
pending stage: execute pending callback. Generally speaking, all IO callbacks (network, file, DNS) will be executed in the Poll IO stage, but in some cases, the callback of the Poll IO stage will be delayed until the next loop execution, so this callback is executed in the pending stage For example, if there is an error in the IO callback or the writing of data is successful, the callback will be executed in the pending phase of the next event loop.
-
Idle stage: The event loop will be executed every time (idle does not mean that the event loop will be executed when it is idle).
-
The prepare phase: similar to the idle phase.
-
Poll IO stage: call the IO multiplexing interface provided by each platform (for example, epoll mode under Linux), wait for the timeout time at most, and execute the corresponding callback when returning.
The calculation rule of timeout:
- timeout is 0 if the time loop is running in UV_RUN_NOWAIT mode.
- If the time loop is about to exit (uv_stop was called), timeout is 0.
- If there is no active handle or request, the timeout is 0.
- If there are nodes in the queue with the idle phase, the timeout is 0.
- If there is a handle waiting to be closed (that is, uv_close is adjusted), the timeout is 0.
- If none of the above is satisfied, take the node with the fastest timeout in the timer phase as timeout.
- If none of the above is satisfied, the timeout is equal to -1, that is, it will block until the condition is satisfied.
- Check stage: same as idle and prepare. 9. Closing phase: Execute the callback passed in when calling the uv_close function. 10. If
Libuv is running in UV_RUN_ONCE mode, the event loop is about to exit. But there is a situation that the timeout value of the Poll IO stage is the value of the node in the timer stage, and the Poll IO stage is returned because of the timeout, that is, no event occurs, and no IO callback is executed.
At this time, it needs to be executed once timer stage. Because a node timed out. 11. One round of event loop ends. If Libuv runs in UV_RUN_NOWAIT or UV_RUN_ONCE mode, it exits the event loop. If it runs in UV_RUN_DEFAULT mode and the status is alive, the next round of loop starts. Otherwise exit the event loop.
Below I can understand the basic principle of libuv through an example.
#include
#include
int64_t counter = 0;
void wait_for_a_while(uv_idle_t* handle) {
counter++;
if (counter >= 10e6)
uv_idle_stop(handle);
}
int main() {
uv_idle_t idler;
// Get the core structure of the event loop. and initialize an idle
uv_idle_init(uv_default_loop(), &idler);
// Insert a task into the idle phase of the event loop uv_idle_start(&idler, wait_for_a_while);
// Start the event loop uv_run(uv_default_loop(), UV_RUN_DEFAULT);
// Destroy libuv related data uv_loop_close(uv_default_loop());
return 0;
}
To use Libuv, we first need to obtain uv_loop_t, the core structure of Libuv. uv_loop_t is a very large structure, which records the data of the entire life cycle of Libuv. uv_default_loop provides us with a uv_loop_t structure that has been initialized by default. Of course, we can also allocate one and initialize it ourselves.
uv_loop_t* uv_default_loop(void) {
// cache if (default_loop_ptr != NULL)
return default_loop_ptr;
if (uv_loop_init(&default_loop_struct))
return NULL;
default_loop_ptr = &default_loop_struct;
return default_loop_ptr;
}
Libuv maintains a global uv*loop_t structure, which is initialized with uv_loop_init, and does not intend to explain the uv_loop_init function, because it probably initializes each field of the uv_loop_t structure. Then we look at the functions of the uv_idle* series.
1 uv_idle_init
int uv_idle_init(uv_loop_t* loop, uv_idle_t* handle) {
/*
Initialize the type of handle, belong to the loop, mark UV_HANDLE_REF,
And insert handle into the end of the loop->handle_queue queue */
uv__handle_init(loop, (uv_handle_t*)handle, UV_IDLE);
handle->idle_cb = NULL;
return 0;
}
After executing the uv_idle_init function, the memory view of Libuv is shown in the following figure
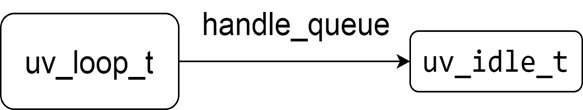
2 uv_idle_start
int uv_idle_start(uv_idle_t* handle, uv_idle_cb cb) {
// If the start function has been executed, return directly if (uv__is_active(handle)) return 0;
// Insert the handle into the idle queue in the loop QUEUE_INSERT_HEAD(&handle->loop->idle_handles, &handle->queue);
// Mount the callback, which will be executed in the next cycle handle->idle_cb = cb;
/*
Set the UV_HANDLE_ACTIVE flag bit, and increase the number of handles in the loop by one,
When init, just mount the handle to the loop, when start, the handle is in the active state*/
uv__handle_start(handle);
return 0;
}
The memory view after executing uv_idle_start is shown in the following figure.
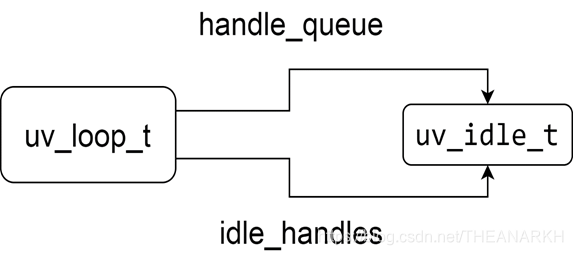
Then execute uv_run to enter Libuv's event loop.
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
// Submit the task to loop before uv_run
r = uv__loop_alive(loop);
// no tasks to process or uv_stop called
while (r != 0 && loop->stop_flag == 0) {
// Process the idle queue uv__run_idle(loop);
}
// exited because uv_stop was called, reset the flag
if (loop->stop_flag != 0)
loop->stop_flag = 0;
/*
Returns whether there are still active tasks (handle or request),
The agent can execute uv_run again
*/
return r;
When the handle queue, Libuv will exit. Later, we will analyze the principle of Libuv event loop in detail.
1.1.3 Other third-party libraries
The third-party libraries in Node.js include asynchronous DNS parsing (cares), HTTP parser (the old version uses http_parser, the new version uses llhttp), HTTP2 parser (nghttp2), decompression and compression library (zlib ), encryption and decryption library (openssl), etc., not introduced one by one.
1.2 How Node.js works
1.2.1 How does Node.js extend JS functionality?
V8 provides a mechanism that allows us to call the functions provided by C++ and C language modules at the JS layer. It is through this mechanism that Node.js realizes the expansion of JS capabilities. Node.js does a lot of things at the bottom layer, implements many functions, and then exposes the interface to users at the JS layer, which reduces user costs and improves development efficiency.
1.2.2 How to add a custom function in V8?
// Define Handle in C++ Test = FunctionTemplate::New(cb);
global->Set(String::New("Test"), Test);
// use const test = new Test() in JS;
We first have a perceptual understanding. In the following chapters, we will specifically explain how to use V8 to expand the functions of JS.
1.2.3 How does Node.js achieve expansion?
Node.js does not expand an object for each function, and then mounts it in a global variable, but expands a process object, and then expands the js function through process.binding. Node.js defines a global JS object process, which maps to a C++ object process, and maintains a linked list of C++ modules at the bottom layer. JS accesses the C++ process object by calling the process.binding of the JS layer, thereby accessing the C++ module ( Similar to accessing JS's Object, Date, etc.). However, Node.js version 14 has been changed to the internalBinding method, and the C++ module can be accessed through the internalBinding. The principle is similar.
1.3 Node.js startup process
The following is the main flowchart of Node.js startup, as shown in Figure 1-4.
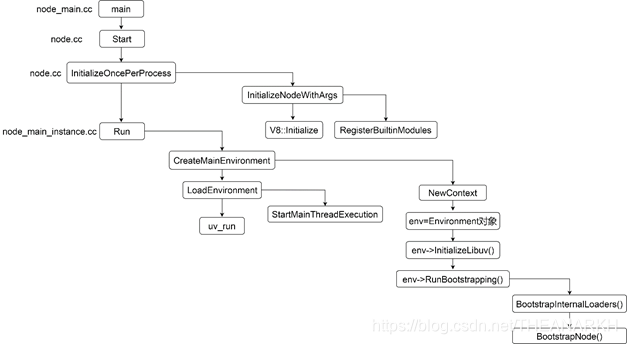
Let's go from top to bottom and look at what each process does.
1.3.1 Registering C++ modules
The function of the RegisterBuiltinModules function (node_binding.cc) is to register C++ modules.
void RegisterBuiltinModules() {
#define V(modname) _register_##modname();
NODE_BUILTIN_MODULES(V)
#undef V
}
NODE_BUILTIN_MODULES is a C language macro, which is expanded as follows (omitting similar logic)
void RegisterBuiltinModules() {
#define V(modname) _register_##modname();
V(tcp_wrap)
V(timers)
...other modules #undef V
}
Further expand as follows
void RegisterBuiltinModules() {
_register_tcp_wrap();
_register_timers();
}
A series of functions starting with _register are executed, but we cannot find these functions in the Node.js source code, because these functions are defined by macros in the file defined by each C++ module (the last line of the .cc file). Take the tcp_wrap module as an example to see how it does it. The last sentence of the code in the file tcp_wrap.cc NODE_MODULE_CONTEXT_AWARE_INTERNAL(tcp_wrap, node::TCPWrap::Initialize) macro expansion is
#define NODE_MODULE_CONTEXT_AWARE_INTERNAL(modname, regfunc)
NODE_MODULE_CONTEXT_AWARE_CPP(modname,
regfunc,
nullptr,
NM_F_INTERNAL)
Continue to expand
#define NODE_MODULE_CONTEXT_AWARE_CPP(modname, regfunc, priv, flags
static node::node_module _module = {
NODE_MODULE_VERSION,
flags,
nullptr,
**FILE**,
nullptr,
(node::addon_context_register_func)(regfunc),
NODE_STRINGIFY(modname),
priv,
nullptr};
void _register_tcp_wrap() { node_module_register(&_module); }
We see that the bottom layer of each C++ module defines a function starting with _register. When Node.js starts, these functions will be executed one by one. Let's continue to look at what these functions do, but before that, let's take a look at the data structures that represent C++ modules in Node.js.
struct node_module {
int nm_version;
unsigned int nm_flags;
void* nm_dso_handle;
const char* nm_filename;
node::addon_register_func nm_register_func;
node::addon_context_register_func nm_context_register_func;
const char* nm_modname;
void* nm_priv;
struct node_module* nm_link;
};
We see that the function at the beginning of _register calls node_module_register and passes in a node_module data structure, so let's take a look at the implementation of node_module_register
void node_module_register(void* m) {
struct node_module* mp = reinterpret_cast (m);
if (mp->nm_flags & NM_F_INTERNAL) {
mp->nm_link = modlist_internal;
modlist_internal = mp;
} else if (!node_is_initialized) {
mp->nm_flags = NM_F_LINKED;
mp->nm_link = modlist_linked;
modlist_linked = mp;
} else {
thread_local_modpending = mp;
}
}
We only look at AssignToContext and CreateProperties, set_env_vars will explain the process chapter.
1.1 AssignToContext
inline void Environment::AssignToContext(v8::Local context,
const ContextInfo& info) {
// Save the env object in the context context->SetAlignedPointerInEmbedderData(ContextEmbedderIndex::kEnvironment, this);
// Used by Environment::GetCurrent to know that we are on a node context.
context->SetAlignedPointerInEmbedderData(ContextEmbedderIndex::kContextTag, Environment::kNodeContextTagPtr);
}
AssignToContext is used to save the relationship between context and env. This logic is very important, because when the code is executed later, we will enter the field of V8. At this time, we only know Isolate and context. If we don't save the relationship between context and env, we don't know which env we currently belong to. Let's see how to get the corresponding env.
inline Environment* Environment::GetCurrent(v8::Isolate* isolate) {
v8::HandleScope handle_scope(isolate);
return GetCurrent(isolate->GetCurrentContext());
}
inline Environment* Environment::GetCurrent(v8::Local context) {
return static_cast (
context->GetAlignedPointerFromEmbedderData(ContextEmbedderIndex::kEnvironment));
}
1.2 CreateProperties
Next, let's take a look at the logic of creating a process object in CreateProperties.
Isolate* isolate = env->isolate();
EscapableHandleScope scope(isolate);
Local context = env->context();
// Apply for a function template Local process_template = FunctionTemplate::New(isolate);
process_template->SetClassName(env->process_string());
// Save the function Local generated by the function template process_ctor;
// Save the object Local created by the function generated by the function module process;
if (!process_template->GetFunction(context).ToLocal(&process_ctor)|| !process_ctor->NewInstance(context).ToLocal(&process)) {
return MaybeLocal ();
}
The object saved by the process is the process object we use in the JS layer. When Node.js is initialized, some properties are also mounted.
READONLY_PROPERTY(process,
"version",
FIXED_ONE_BYTE_STRING(env->isolate(),
NODE_VERSION));
READONLY_STRING_PROPERTY(process, "arch", per_process::metadata.arch);......
After creating the process object, Node.js saves the process to env.
Local process_object = node::CreateProcessObject(this).FromMaybe(Local ());
set_process_object(process_object)
1.3.3 Initialize Libuv task
The logic in the InitializeLibuv function is to submit a task to Libuv.
void Environment::InitializeLibuv(bool start*profiler_idle_notifier) {
HandleScope handle_scope(isolate());
Context::Scope context_scope(context());
CHECK_EQ(0, uv_timer_init(event_loop(), timer_handle()));
uv_unref(reinterpret_cast (timer_handle()));
uv_check_init(event_loop(), immediate_check_handle());
uv_unref(reinterpret_cast (immediate_check_handle()));
uv_idle_init(event_loop(), immediate_idle_handle());
uv_check_start(immediate_check_handle(), CheckImmediate);
uv_prepare_init(event_loop(), &idle_prepare_handle*);
uv*check_init(event_loop(), &idle_check_handle*);
uv*async_init(
event_loop(),
&task_queues_async*,
[](uv*async_t* async) {
Environment* env = ContainerOf(
&Environment::task_queues_async*, async);
env->CleanupFinalizationGroups();
env->RunAndClearNativeImmediates();
});
uv*unref(reinterpret_cast (&idle_prepare_handle*));
uv*unref(reinterpret_cast (&idle_check_handle*));
uv*unref(reinterpret_cast (&task_queues_async*));
// …
}
These functions are all provided by Libuv, which are to insert task nodes into different stages of Libuv, and uv_unref is to modify the state.
1 timer_handle is the data structure that implements the timer in Node.js, corresponding to the time phase of Libuv 2 immediate_check_handle is the data structure that implements setImmediate in Node.js, corresponding to the check phase of Libuv.
3 task queues_async is used for sub-thread and main thread communication.
1.3.4 Initialize Loader and Execution Contexts
s.binding = function binding(module) {
module = String(module);
if (internalBindingWhitelist.has(module)) {
return internalBinding(module);
}
throw new Error(`No such module: ${module}`);
};
Mount the binding function in the process object (that is, the process object we usually use). This function is mainly used for built-in JS modules, which we will often see later. The logic of binding is to find the corresponding C++ module according to the module name. The above processing is for Node.js to load C++ modules through the binding function at the JS layer. We know that there are native JS modules (JS files in the lib folder) in Node.js. Next, let's take a look at the processing of loading native JS modules. Node.js defines a NativeModule class that is responsible for loading native JS modules. A variable is also defined to hold the list of names of native JS modules.
static map = new Map(moduleIds.map((id) => [id, new NativeModule(id)]));
The main logic of NativeModule is as follows: 1. The code of the native JS module is converted into characters and stored in the node_javascript.cc file. The NativeModule is responsible for the loading of the native JS module, that is, compilation and execution. 2 Provide a require function to load native JS modules. For modules whose file paths start with internal, they cannot be required by users.
This is the general logic of native JS module loading. Specifically, we will analyze it in the Node.js module loading chapter. After executing internal/bootstrap/loaders.js, finally return three variables to the C++ layer.
return {
internalBinding,
NativeModule,
require: nativeModuleRequire,
};
The C++ layer saves two of the functions, which are used to load the built-in C++ module and the function of the native JS module respectively.
set_internal_binding_loader(internal_binding_loader.As ());
set_native_module_require(require.As ());
So far, internal/bootstrap/loaders.js is analyzed.
2 Initialize the execution context
BootstrapNode is responsible for initializing the execution context, the code is as follows
EscapableHandleScope scope(isolate*);
// Get global variables and set the global property Local global = context()->Global();
global->Set(context(), FIXED_ONE_BYTE_STRING(isolate*, "global"), global).Check();
Parameters process, require, internalBinding, primordials when executing internal/bootstrap/node.js
std::vector > node_params = {
process_string(),
require_string(),
internal_binding_string(),
primordials_string()};
std::vector > node_args = {
process_object(),
// native module loader native_module_require(),
// C++ module loader internal_binding_loader(),
primordials()};
MaybeLocal result = ExecuteBootstrapper(
this, "internal/bootstrap/node", &node_params, &node_args);
Set a global property on the global object, which is the global object we use in Node.js. Then execute internal/bootstrap/node.js to set some variables (refer to internal/bootstrap/node.js for details).
process.cpuUsage = wrapped.cpuUsage;
process.resourceUsage = wrapped.resourceUsage;
process.memoryUsage = wrapped.memoryUsage;
process.kill = wrapped.kill;
process.exit = wrapped.exit;
set global variable
defineOperation(global, 'clearInterval', timers.clearInterval);
defineOperation(global, 'clearTimeout', timers.clearTimeout);
defineOperation(global, 'setInterval', timers.setInterval);
defineOperation(global, 'setTimeout', timers.setTimeout);
ObjectDefineProperty(global, 'process', {
value: process,
enumerable: false,
writable: true,
configurable: true
});
1.3.5 Execute the user JS file
StartMainThreadExecution to perform some initialization work, and then execute the user JS code.
- Mount attributes to the process object
Execute the patchProcessObject function (exported in node_process_methods.cc) to mount some attributes to the process object, not listed one by one.
// process.argv
process->Set(context,
FIXED_ONE_BYTE_STRING(isolate, "argv"),
ToV8Value(context, env->argv()).ToLocalChecked()).Check();
READONLY_PROPERTY(process,
"pid",
Integer::New(isolate, uv_os_getpid()));
Because Node.js adds support for threads, some properties need to be hacked. For example, when process.exit is used in a thread, a single thread is exited instead of the entire process, and functions such as exit need special handling. Later chapters will explain in detail.
- Handling inter-process communication
function setupChildProcessIpcChannel() {
if (process.env.NODE_CHANNEL_FD) {
const fd = parseInt(process.env.NODE_CHANNEL_FD, 10);
delete process.env.NODE_CHANNEL_FD;
const serializationMode =
process.env.NODE_CHANNEL_SERIALIZATION_MODE || "json";
delete process.env.NODE_CHANNEL_SERIALIZATION_MODE;
require("child_process")._forkChild(fd, serializationMode);
}
}
The environment variable NODE_CHANNEL_FD is set when the child process is created. If it is indicated that the currently started process is a child process, inter-process communication needs to be handled.
- I will think deeply or look at its implementation. As we all know, when a server starts, it will listen to a port, which is actually a new socket. Then if a connection arrives, we can get the socket corresponding to the new connection through accept.
Is this socket and the listening socket the same? In fact, sockets are divided into listening type and communication type. On the surface, the server uses one port to realize multiple connections, but this port is used for monitoring, and the bottom layer is used for communication with the client is actually another socket. So every time a connection comes over, the socket responsible for monitoring finds that it is a packet (syn packet) that establishes a connection, and it will generate a new socket to communicate with (the one returned when accepting).
The listening socket only saves the IP and port it is listening on. The communication socket first copies the IP and port from the listening socket, and then records the client's IP and port. When a packet is received next time, the operating system will Find the socket from the socket pool according to the quadruple to complete the data processing.
The serial mode is to pick a node from the queue that has completed the three-way handshake, and then process it. Pick another node and process it again. If there is blocking IO in the process of processing, you can imagine how low the efficiency is. And when the amount of concurrency is relatively large, the queue corresponding to the listening socket will soon be full (the completed connection queue has a maximum length). This is the simplest mode, and although it is certainly not used in the design of the server, it gives us an idea of the overall process of a server handling requests.
1.4.2 Multi-process mode
In serial mode, all requests are queued and processed in one process, which is the reason for inefficiency. At this time, we can divide the request to multiple processes to improve efficiency, because in the serial processing mode, if there is a blocking IO operation, it will block the main process, thereby blocking the processing of subsequent requests. In the multi-process mode, if a request blocks a process, the operating system will suspend the process, and then schedule other processes to execute, so that other processes can perform new tasks. There are several types in multi-process mode.
-
The main process accepts, the child process processes the request
In this mode, the main process is responsible for extracting the node that has completed the connection, and then handing over the request corresponding to this node to the child process for processing. The logic is as follows.
while(1) {
const socketForCommunication = accept(socket);
if (fork() > 0) {
continue;
// parent process } else {
// child process handle(socketForCommunication);
}
}
In this mode, every time a request comes, a new process will be created to handle it. This mode is slightly better than serial. Each request is processed independently. Assuming that a request is blocked in file IO, it will not affect the processing of b request, and it is as concurrent as possible. Its bottleneck is that the number of processes in the system is limited. If there are a large number of requests, the system cannot handle it. Furthermore, the overhead of the process is very large, which is a heavy burden for the system.
- Process Pool Mode Creating and destroying processes in real time is expensive and inefficient, so the process pool mode is derived. The process pool mode is to create a certain number of processes in advance when the server starts, but these processes are worker processes. It is not responsible for accepting requests. It is only responsible for processing requests. The main process is responsible for accept, and it hands the socket returned by accept to the worker process for processing, as shown in the figure below.

However, compared with the mode in 1, the process pool mode is relatively complicated, because in mode 1, when the main process receives a request, it will fork a child process in real time. At this time, the child process will inherit the new request in the main process. The corresponding fd, so it can directly process the request corresponding to the fd.
In the process pool mode, the child process is created in advance. When the main process receives a request, the child process cannot get the fd corresponding to the request. of. At this time, the main process needs to use the technique of passing file descriptors to pass the fd corresponding to this request to the child process. A process is actually a structure task_struct. In JS, we can say it is an object. It has a field that records the open file descriptor. When we access a file descriptor, the operating system will be based on the value of fd.
Find the underlying resource corresponding to fd from task_struct, so when the main process passes the file descriptor to the child process, it passes more than just a number fd, because if you only do this, the fd may not correspond to any resources in the child process, Or the corresponding resources are inconsistent with those in the main process. The operating system does a lot of things for us. Let us access the correct resource through fd in the child process, that is, the request received in the main process.
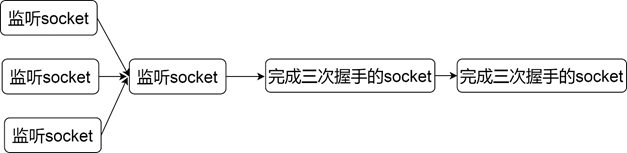
- child process accept
This mode is not to wait until the request comes and then create the process. Instead, when the server starts, multiple processes are created. Then multiple processes call accept respectively. The architecture of this mode is shown in Figure 1-8.
const socketfd = socket (configuration such as protocol type);
bind(socketfd, listening address)
for (let i = 0 ; i < number of processes; i++) {
if (fork() > 0) {
// The parent process is responsible for monitoring the child process} else {
// The child process handles the request listen(socketfd);
while(1) {
const socketForCommunication = accept(socketfd);
handle(socketForCommunication);
}
}
}
In this mode, multiple child processes are blocked in accept. If a request arrives at this time, all child processes will be woken up, but the child process that is scheduled first will take off the request node first. After the subsequent process is woken up, it may encounter that there is no request to process, and enter again. Sleep, the process is woken up ineffectively, which is the famous phenomenon of shocking herd. The improvement method is to add a lock before accept, and only the process that gets the lock can accept, which ensures that only one process will be blocked in accept. Nginx solves this problem, but the new version of the operating system has solved this problem at the kernel level. Only one process will be woken up at a time. Usually this pattern is used in conjunction with event-driven.
1.4.3 Multi-threading mode
Multi-threading mode is similar to multi-process mode, and it is also divided into the following
types:
- main process accept
- create sub-thread processing
- sub-thread accept
- The first two thread pools are the same as in the multi-process mode, but the third one is special, and we mainly introduce the third one. In the subprocess mode, each subprocess has its own task_struct, which means that after fork, each process is responsible for maintaining its own data, while the thread is different. The thread shares the data of the main thread (main process). , when the main process gets an fd from accept, if it is passed to the thread, the thread can operate directly. So in the thread pool mode, the architecture is shown in the following figure.
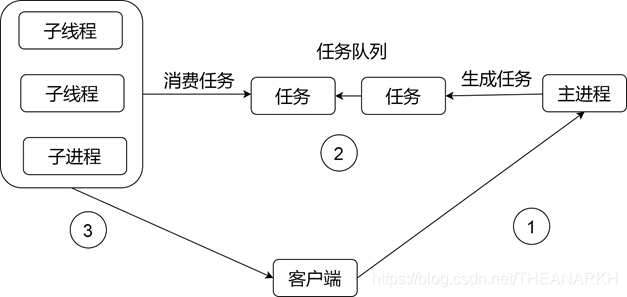
The main process is responsible for accepting the request, and then inserting a task into the shared queue through mutual exclusion. The child threads in the thread pool also extract nodes from the shared queue for processing through mutual exclusion.
1.4.4 Event-driven
Many servers (Nginx, Node.js, Redis) are now designed using the event-driven pattern. We know from previous design patterns that in order to handle a large number of requests, the server needs a large number of processes/threads. This is a very large overhead.
The event-driven mode is generally used with a single process (single thread). But because it is a single process, it is not suitable for CPU intensive, because if a task keeps occupying the CPU, subsequent tasks cannot be executed. It is more suitable for IO-intensive (generally provides a thread pool, responsible for processing CPU or blocking tasks). When using the multi-process/thread mode, a process/thread cannot occupy the CPU all the time.
After a certain period of time, the operating system will perform task scheduling. Let other threads also have the opportunity to execute, so that the previous tasks will not block the later tasks and starvation will occur. Most operating systems provide event-driven APIs. But event-driven is implemented differently in different systems. So there is usually a layer of abstraction to smooth out this difference. Here is an example of Linux epoll.
// create an epoll
var epollFD = epoll_create();
/*
Register an event of interest for a file descriptor in epoll, here is the listening socket, register a readable event, that is, the connection is coming event = {
event: readable fd:
Libuv data structure and general logic
2.1 Core structure uv_loop_s
uv_loop_s is the core data structure of Libuv, and each event loop corresponds to a uv_loop_s structure. It records core data throughout the event loop. Let's analyze the meaning of each field.
1 Field void* data of user-defined data;
2 The number of active handles, which will affect the use of the loop to exit unsigned int active_handles;
3 handle queue, including active and inactive void* handle_queue[2];
The number of 4 requests will affect the exit of the event loop union { void* unused[2]; unsigned int count; } active_reqs;
5 The flag for the end of the event loop unsigned int stop_flag;
6 Some flags run by Libuv, currently only UV_LOOP_BLOCK_SIGPROF, mainly used to block the SIGPROF signal when epoll_wait, improve performance, SIGPROF is a signal unsigned long flags triggered by the setting of the operating system settimer function;
7 fd of epoll
int backend_fd;
8 pending stage queue void* pending_queue[2];
9 points to the uv__io_t structure queue that needs to register events in epoll void* watcher_queue[2];
10 There is an fd field in the node of the watcher_queue queue, watchers use fd as the index, record the uv__io_t structure uv__io_t** watchers where fd is located;
11 The number of watchers related, set unsigned int nwatchers in maybe_resize function;
12 The number of fds in watchers, generally the number of nodes in the watcher_queue queue unsigned int nfds;
13 After the child thread of the thread pool processes the task, insert the corresponding structure into the wq queue void* wq[2];
14 Control the mutually exclusive access of the wq queue, otherwise there will be problems with simultaneous access by multiple child threads uv_mutex_t wq_mutex;
15 for the sub-thread of the thread pool and the main thread to communicate uv_async_t wq_async;
16 Mutex variable for read-write lock uv_rwlock_t cloexec_lock;
17 Queue in the close phase of the event loop, generated by uv_close uv_handle_t* closing_handles;
18 Process queue from fork void* process_handles[2];
19 Task queue corresponding to the prepare phase of the event loop void* prepare_handles[2];
20 Task queue corresponding to the check phase of the event loop void* check_handles[2];
21 The task queue corresponding to the idle phase of the event loop void* idle_handles[2];
21 async_handles queue, the Poll IO stage executes uv_async_io to traverse the async_handles queue to process the node with pending 1 void* async_handles[2];
22 is used to monitor whether there is an async handle task that needs to be processed uv__io_t async_io_watcher;
23 The write side fd used to save the communication between the child thread and the main thread
int async_wfd;
24 Save the timer binary heap structure struct {
void* min;
unsigned int nelts;
} timer_heap;
25 Manage the id of the timer node, and continuously superimpose uint64_t timer_counter;
26 At the current time, Libuv will update the current time at the beginning of each event loop and in the Poll IO stage, and then use it in subsequent stages to reduce the uint64_t time for system calls;
27 The pipeline used for the communication between the forked process and the main process, used to notify the main process when the child process receives a signal, and then the main process executes the callback registered by the child process node int signal_pipefd[2];
28 Similar to async_io_watcher, signal_io_watcher saves the pipeline read end fd and callback, and then registers it in epoll. When the child process receives the signal, it writes to the pipeline through write, and finally executes the callback uv_io_t signal_io_watcher in the Poll IO stage;
29 handle used to manage the exit signal of the child process
uv_signal_t child_watcher;
30 spare fd
int emfile_fd;
2.2 uv_handle_t
In Libuv, uv_handle_t is similar to the base class in C++, and many subclasses inherit from it. Libuv mainly obtains the effect of inheritance by controlling the layout of memory. handle represents an object with a long life cycle. E.g 1 An active prepare handle whose callback will be executed each time the event loops.
2 A TCP handle executes its callback every time a connection arrives.
Let's take a look at uv_handle_t Definition of
1 Custom data, used to associate some contexts, used in Node.js to associate the C++ object void\* data to which handle belongs;
2 belongs to the event loop uv_loop_t\* loop;
3 handle type uv_handle_type type;
4 After the handle calls uv_close, the callback uv_close_cb that is executed in the closing phase close_cb;
5 The front and rear pointers used to organize the handle queue void\* handle_queue[2];
6 file descriptor union {
int fd;
void\* reserved[4];
} u;
7 When the handle is in the close queue, this field points to the next close node uv_handle_t\* next_closing;
8 handle status and flag unsigned int flags;
2.2.1 uv_stream_s
uv_stream_s is a structure representing a stream. In addition to inheriting the fields of uv_handle_t, it additionally defines the following fields
1 The number of bytes waiting to be sent size_t write_queue_size;
2 Function to allocate memory uv_alloc_cb alloc_cb;
3 Callback uv_read_cb read_cb executed when reading data is successful;
4 Initiate the structure corresponding to the connection uv_connect_t \*connect_req;
5 Close the structure uv_shutdown_t \*shutdown_req corresponding to the write end;
6 Used to insert epoll, register read and write events uv\_\_io_t io_watcher;
7 queue to be sent void\* write_queue[2];
8 Send completed queue void\* write_completed_queue[2];
9 Callback uv_connection_cb connection_cb executed when connection is received;
10 Error code for socket operation failure int delayed_error;
11 fd returned by accept
int accepted_fd;
12 An fd has been accepted, and there is a new fd, temporarily stored void\* queued_fds;
2.2.2 uv_async_s
uv_async_s is a structure that implements asynchronous communication in Libuv. Inherited from uv_handle_t and additionally defines the following fields.
1 Callback uv_async_cb executed when an asynchronous event is triggered async_cb;
2 is used to insert the async-handles queue void* queue[2];
3 The node pending field in the async_handles queue is 1, indicating that the corresponding event has triggered int pending;
2.2.3 uv_tcp_s
uv_tcp_s inherits uv_handle_s and uv_stream_s.
2.2.4 uv_udp_s
1 send bytes size_t send_queue_size;
2 The number of write queue nodes size_t send_queue_count;
3 Allocate the memory for receiving data uv_alloc_cb alloc_cb;
4 Callback uv_udp_recv_cb recv_cb executed after receiving data;
5 Insert the IO watcher in epoll to realize data read and write uv__io_t io_watcher;
6 queue to be sent void* write_queue[2];
7 Send the completed queue (success or failure to send), related to the queue to be sent void* write_completed_queue[2];
2.2.5 uv_tty_s
uv_tty_s inherits from uv_handle_t and uv_stream_t. The following fields are additionally defined.
1 The parameters of the terminal struct termios orig_termios;
2 The working mode of the terminal int mode;
2.2.6 uv_pipe_s
uv_pipe_s inherits from uv_handle_t and uv_stream_t. The following fields are additionally defined.
1 marks whether the pipe can be used to pass the file descriptor int ipc;
2 File path for Unix domain communication const char* pipe_fname;
2.2.7 uv_prepare_s, uv_check_s, uv_idle_s
The above three structure definitions are similar, they all inherit uv_handle_t and define two additional fields.
1 prepare, check, idle stage callback uv_xxx_cb xxx_cb;
2 is used to insert prepare, check, idle queue void* queue[2];
2.2.8 uv_timer_s
uv_timer_s inherits uv_handle_t and additionally defines the following fields.
1 timeout callback uv_timer_cb timer_cb;
2 Insert the field of the binary heap void* heap_node[3];
3 timeout uint64_t timeout;
4 Whether to continue to re-time after the timeout, if so, re-insert the binary heap uint64_t repeat;
5 id mark, used to compare uint64_t start_id when inserting binary heap
2.2.9 uv_process_s
uv_process_s inherits uv_handle_t and additionally defines
1 Callback executed when the process exits uv_exit_cb exit_cb;
2 process id
int pid;
3 for inserting queues, process queues or pending queues void\* queue[2];
4 Exit code, set int status when the process exits;
2.2.10 uv_fs_event_s
uv_fs_event_s is used to monitor file changes. uv_fs_event_s inherits uv_handle_t and additionally defines
1 Monitored file path (file or directory)
char\* path;
2 The callback uv_fs_event_cb cb executed when the file changes;
2.2.11 uv_fs_poll_s
uv_fs_poll_s inherits uv_handle_t and additionally defines
1 poll_ctx points to poll_ctx structure void\* poll_ctx;
struct poll*ctx {
// corresponding handle
uv_fs_poll_t* parent_handle;
// Mark whether to start polling and the reason for failure when polling int busy_polling;
// How often to check if the file content has changed unsigned int interval;
// The start time of each round of polling uint64_t start_time;
// belongs to the event loop uv_loop_t* loop;
// Callback when the file changes uv_fs_poll_cb poll_cb;
// Timer for polling uv_timer_t timer_handle after timing timeout;
// Record the context information of polling, file path, callback, etc. uv_fs_t fs_req;
// Save the file information returned by the operating system when polling uv_stat_t statbuf;
// The monitored file path, the string value is appended to the structure char path[1]; /* variable length \_/
};
2.2.12 uv_poll_s
uv_poll_s inherits from uv_handle_t and additionally defines the following fields.
1 Callback uv_poll_cb poll_cb executed when the monitored fd has an event of interest;
2 Save the IO watcher of fd and callback and register it in epoll uv__io_t io_watcher;
2.1.13 uv_signal_s
uv_signal_s inherits uv_handle_t and additionally defines the following fields
1 Callback uv_signal_cb signal_cb when a signal is received;
2 registered signal int signum;
3 It is used to insert the red-black tree. The process encapsulates the signals and callbacks of interest into uv_signal_s, and then inserts it into the red-black tree. When the signal arrives, the process writes the notification to the pipeline in the signal processing number to notify Libuv. Libuv will execute the callback corresponding to the process in the Poll IO stage. The definition of a red-black tree node is as follows struct {
struct uv_signal_s* rbe_left;
struct uv_signal_s* rbe_right;
struct uv_signal_s\* rbe_parent;
int rbe_color;
} tree_entry;
4 Number of received signals unsigned int caught_signals;
5 Number of processed signals unsigned int dispatched_signals;
2.3 uv_req_s
Send the callback for execution (success or failure) uv_udp_send_cb send_cb;
### 2.3.5 uv_getaddrinfo_s
uv_getaddrinfo_s represents a DNS request to query IP through domain name, additionally defined field
```cpp
1 belongs to the event loop uv_loop_t\* loop;
2 Node struct uv\_\_work work_req for inserting into the thread pool task queue during asynchronous DNS resolution;
3 Callback uv_getaddrinfo_cb cb executed after DNS resolution;
4 DNS query configuration struct addrinfo* hints;
char* hostname;
char\* service;
5 DNS resolution result struct addrinfo\* addrinfo;
6 DNS resolution return code int retcode;
2.3.6 uv_getnameinfo_s
uv_getnameinfo_s represents a DNS query request to query the domain name through IP, and the additionally defined field
1 belongs to the event loop uv_loop_t\* loop;
2 Node struct uv\_\_work work_req for inserting into the thread pool task queue during asynchronous DNS resolution;
3 Callback for socket transfer domain name completion uv_getnameinfo_cb getnameinfo_cb;
4 The socket structure struct sockaddr_storage storage that needs to be transferred to the domain name;
5 Indicates the information returned by the query int flags;
6 Query the returned information char host[NI_MAXHOST];
char service[NI_MAXSERV];
7 Query return code int retcode;
2.3.7 uv_work_s
uv_work_s is used to submit tasks to the thread pool, additionally defined fields
1 belongs to the event loop uv_loop_t\* loop;
2 Function uv_work_cb work_cb for processing tasks;
3 The function uv_after_work_cb after_work_cb executed after the task is processed;
4 Encapsulate a work and insert it into the thread pool queue. The work and done functions of work_req are the encapsulation of the above work_cb and after_work_cb struct uv\_\_work work_req;
uv_fs_s
uv_fs_s represents a file operation request, additionally defined fields
1 file operation type uv_fs_type fs_type;
2 belongs to the event loop uv_loop_t\* loop;
3 Callback uv_fs_cb cb for file operation completion;
4 Return code of file operation ssize_t result;
5 Data returned by file operation void\* ptr;
6 File operation path const char\* path;
7 stat information of the file uv_stat_t statbuf;
8 When the file operation involves two paths, save the destination path const char \*new_path;
9 file descriptor uv_file file;
10 file flags int flags;
11 Operation mode mode_t mode;
12 The data and number passed in when writing the file unsigned int nbufs;
uv_buf_t\* bufs;
13 file offset off_t off;
14 Save the uid and gid that need to be set, such as uv_uid_t uid when chmod;
uv_gid_t gid;
15 Save the file modification and access time that need to be set, such as double atime when fs.utimes;
double mtime;
16 When asynchronous, it is used to insert the task queue, save the work function, and call back the function struct uv\_\_work work_req;
17 Save the read data or length. e.g. read and sendfile
uv_buf_t bufsml[4];
2.4 IO Observer
IO observer is the core concept and data structure in Libuv. Let's take a look at its definition
1 struct uv\_\_io_s {
2 // Callback after the event is triggered 3. uv\_\_io_cb cb;
3 // Used to insert the queue 5. void\* pending_queue[2];
4 void\* watcher_queue[2];
5 // Save the event of interest this time and set it when inserting the IO observer queue 8. unsigned int pevents;
6 // Save the current events of interest 10. unsigned int events;
7 int fd;
8 };
The IO observer encapsulates the file descriptor, events and callbacks, and then inserts it into the IO observer queue maintained by the loop. In the Poll IO stage, Libuv will register the file descriptor with the underlying event-driven module according to the information described by the IO observer. events of interest. When the registered event is triggered, the callback of the IO observer will be executed. Let's look at some logic of how to start the IO observer.
2.4.1 Initialize IO observer
1 void uv**io_init(uv**io_t\* w, uv\_\_io_cb cb, int fd) {
2 // Initialize the queue, callback, fd that needs to be monitored
3 QUEUE_INIT(&w->pending_queue);
4 QUEUE_INIT(&w->watcher_queue);
5 w->cb = cb;
6 w->fd = fd;
7 // Events of interest when epoll was added last time, set 8. w->events = 0;
8 // Currently interested events, set 10. w->pevents = 0 before executing the epoll function again
9 }
2.4.2 Register an IO observer to Libuv.
1. void uv__io_start(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
2. // Set the current events of interest 3. w->pevents |= events;
4. // May need to expand 5. maybe_resize(loop, w->fd + 1);
6. // If the event has not changed, return directly 7. if (w->events == w->pevents)
7. if ((unsigned) w->fd >= loop->nwatchers)
8. return;
9. // If the IO watcher is not mounted elsewhere, insert it into Libuv's IO watcher queue 10. if (QUEUE_EMPTY(&w->watcher_queue))
11. QUEUE_INSERT_TAIL(&loop->watcher_queue, &w->watcher_queue);
12. // Save the mapping relationship 13. if (loop->watchers[w->fd] == NULL) {
14. loop->watchers[w->fd] = w;
15. loop->nfds++;
16. }
The uv__io_start function is to insert an IO observer into the observer queue of Libuv, and save a mapping relationship in the watchers array. Libuv will process the IO observer queue during the Poll IO phase.
2.4.3 Cancel the IO observer or the event uv
__io_stop to modify the events that the IO observer is interested in. If there are still interesting events, the IO observer will still be in the queue, otherwise it will be removed from
1. void uv\_\_io_stop(uv_loop_t\* loop,
2. uv\_\_io_t\* w,
3. unsigned int events) {
4. if (w->fd == -1)
5. return;
6. assert(w->fd >= 0);
7. if ((unsigned) w->fd >= loop->nwatchers)
8. return;
9. // Clear the previously registered events and save them in pevents, indicating the currently interesting events 10. w->pevents &= ~events;
10. // Not interested in all events 12. if (w->pevents == 0) {
11. // Remove the IO watcher queue 14. QUEUE_REMOVE(&w->watcher_queue);
12. // reset 16. QUEUE_INIT(&w->watcher_queue);
mark, and record the number of active handles plus one. Only handles in REF and ACTIVE state will affect the exit of the event loop.
2.5.4 uv__req_init
uv__req_init initializes the type of request and records the number of requests, which will affect the exit of the event loop.
1. #define uv__req_init(loop, req, typ)
2. do {
3. (req)->type = (typ);
4. (loop)->active_reqs.count++;
5. }
6. while (0)
2.5.5. uv__req_register
The number of requests plus one
1. #define uv\_\_req_register(loop, req)
2. do {
3. (loop)->active_reqs.count++;
4. }
5. while (0)
2.5.6. uv__req_unregister
The number of requests minus one
1. #define uv__req_unregister(loop, req)
2. do {
3. assert(uv__has_active_reqs(loop));
4. (loop)->active_reqs.count--;
5. }
6. while (0)
2.5.7. uv__handle_ref
uv__handle_ref marks the handle as the REF state. If the handle is in the ACTIVE state, the number of active handles is increased by one
1. #define uv\_\_handle_ref(h)
2. do {
3. if (((h)->flags & UV_HANDLE_REF) != 0) break;
4. (h)->flags |= UV_HANDLE_REF;
5. if (((h)->flags & UV_HANDLE_CLOSING) != 0) break;
6. if (((h)->flags & UV_HANDLE_ACTIVE) != 0) uv\_\_active_handle_add(h);
7. }
8. while (0)
9. uv\_\_handle_unref
uv__handle_unref removes the REF state of the handle. If the handle is in the ACTIVE state, the number of active handles is reduced by one
1. #define uv\_\_handle_unref(h)
2. do {
3. if (((h)->flags & UV_HANDLE_REF) == 0) break;
4. (h)->flags &= ~UV_HANDLE_REF;
5. if (((h)->flags & UV_HANDLE_CLOSING) != 0) break;
6. if (((h)->flags & UV_HANDLE_ACTIVE) != 0) uv\_\_active_handle_rm(h);
7. }
8. while (0)
Event Loop
Node.js belongs to the single-threaded event loop architecture. The event loop is implemented by the uv_run function of Libuv. The while loop is executed in this function, and then the event callbacks of each phase are continuously processed.
The processing of the event loop is equivalent to a consumer, consuming tasks generated by various codes. After Node.js is initialized, it begins to fall into the event loop, and the end of the event loop also means the end of Node.js. Let's take a look at the core code of the event loop.
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
// Submit the task to loop before uv_run
r = uv__loop_alive(loop);
// The event loop has no tasks to execute and is about to exit. Set the time of the current loop if (!r)
uv__update_time(loop);
// Exit the event loop if there is no task to process or uv_stop is called while (r != 0 && loop->stop_flag == 0) {
// Update the time field of loop uv__update_time(loop);
// Execute timeout callback uv__run_timers(loop);
/*
Execute the pending callback, ran_pending represents whether the pending queue is empty,
i.e. no node can execute */
ran_pending = uv__run_pending(loop);
// Continue to execute various queues uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
/*
When the execution mode is UV_RUN_ONCE, if there is no pending node,
Only blocking Poll IO, the default mode is also */
if ((mode == UV_RUN_ONCE && !ran_pending) ||
mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
// Poll IO timeout is the timeout of epoll_wait uv__io_poll(loop, timeout);
// Process the check phase uv__run_check(loop);
// handle the close phase uv__run_closing_handles(loop);
/*
There is also a chance to execute the timeout callback, because uv__io_poll may return because the timer expired.
*/
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
/*
Execute only once, exit the loop, UV_RUN_NOWAIT means that it will not block in the Poll IO stage and the loop will only execute once */
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
// exited because uv_stop was called, reset the flag
if (loop->stop_flag != 0)
loop->stop_flag = 0;
/*
Returns whether there are still active tasks (handle or request),
The agent can execute uv_run again
*/
return r;
}
Libuv is divided into several stages. The following is from first to last, and the relevant codes of each stage are analyzed separately.
3.1 Event loop timer In Libuv
the timer stage is the first stage to be processed. The timer is implemented as a min heap, and the node that expires the fastest is the root node. Libuv caches the current time at the beginning of each event loop.
In each round of the event loop, the cached time is used. When necessary, Libuv will explicitly update this time, because the operation needs to be called to obtain the time. The interface provided by the system, and frequently calling the system call will bring a certain amount of time. The cache time can reduce the calls of the operating system and improve the performance.
After Libuv caches the current latest time, it executes uv__run_timers, which traverses the minimum heap and finds the current timeout node. Because the nature of the heap is that the parent node is definitely smaller than the child. And the root node is the smallest, so if a root node, it doesn't time out, the following nodes also don't time out. For the node that times out, its callback is executed. Let's look at the specific logic.
void uv__run_timers(uv_loop_t* loop) {
struct heap_node* heap_node;
uv_timer_t* handle;
// Traverse the binary heap for (;;) {
// Find the smallest node heap_node = heap_min(timer_heap(loop));
// if not exit if (heap_node == NULL)
break;
// Find the first address of the structure through the structure field handle = container_of(heap_node, uv_timer_t, heap_node);
// The smallest node does not have a supermarket, and the subsequent nodes will not time out if (handle->timeout > loop->time)
break;
// delete the node uv_timer_stop(handle);
/*
Retry inserting into the binary heap, if necessary (repeat is set, such as setInterval)
*/
uv_timer_again(handle);
// Execute callback handle->timer_cb(handle);
}
}
After executing the callback, there are two key operations, the first is stop, and the second is again. The logic of stop is very simple, that is, delete the handle from the binary heap and modify the state of the handle.
So what is again? again is to support the scenario of setInterval. If the handle is set with the repeat flag, the handle will continue to execute the timeout callback after every repeat time after the handle times out. For setInterval, the timeout is x, and the callback is executed after every x time.
This is the underlying principle of timers in Node.js. But Node.js does not insert a node into the min heap every time setTimeout/setInterval is adjusted. In Node.js, there is only one handle about uv_timer_s, which maintains a data structure in the JS layer, and calculates the earliest expiration every time. node, and then modify the timeout time of the handle, which is explained in the timer chapter.
In addition, the timer stage is also related to the Poll IO stage, because Poll IO may cause the main thread to block. In order to ensure that the main thread can execute the timer callback as soon as possible, Poll IO cannot block all the time, so at this time, the blocking time is the fastest The duration of the timer node of the period (for details, please refer to the uv_backend_timeout function in libuv core.c).
3.2 pending stage
The official website's explanation of the pending stage is that the IO callbacks that were not executed in the Poll IO stage of the previous round will be executed in the pending stage of the next round of loops.
From the source code point of view, when processing tasks in the Poll IO stage, in some cases, if the currently executed operation fails, a callback function needs to be executed to notify the caller of some information.
The callback function will not be executed immediately, but will be pending in the next round of the event loop. Stage execution (such as successful writing of data, or callback to the C++ layer when the TCP connection fails), let's first look at the processing of the pending stage.
static int uv__run_pending(uv_loop_t* loop) {
QUEUE* q;
QUEUE pq;
uv__io_t* w;
if (QUEUE_EMPTY(&loop->pending_queue))
return 0;
// Move the node of the pending_queue queue to pq, that is, clear the pending_queue
QUEUE_MOVE(&loop->pending_queue, &pq);
// Traverse the pq queue while (!QUEUE_EMPTY(&pq)) {
// Take out the current first node to be processed, ie pq.next
q = QUEUE_HEAD(&pq);
// Remove the current node to be processed from the queue QUEUE_REMOVE(q);
/*
Reset the prev and next pointers, because at this time these two pointers point to the two nodes in the queue */
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, pending_queue);
w->cb(loop, w, POLLOUT);
}
return 1;
}
The processing logic of the pending phase is to execute the nodes in the pending queue one by one. Let's take a look at how the nodes of the pending queue are produced.
void uv__io_feed(uv_loop_t* loop, uv__io_t* w) {
if (QUEUE_EMPTY(&w->pending_queue))
QUEUE_INSERT_TAIL(&loop->pending_queue, &w->pending_queue);
}
Libuv generates pending tasks through the uvio_feed function. From the Libuv code, we will call this function when we see IO errors (such as the uvtcp_connect function of tcp.c).
if (handle->delayed_error)
uv__io_feed(handle->loop, &handle->io_watcher);
After the data is written successfully (such as TCP, UDP), a node is also inserted into the pending queue, waiting for a callback. For example, the code executed after sending data successfully (uv__udp_sendmsg function of udp.c)
// Move out of the write queue after sending QUEUE_REMOVE(&req->queue);
// Join the write completion queue QUEUE_INSERT_TAIL(&handle->write_completed_queue, &req->queue);
/*
After some node data is written, insert the IO observer into the pending queue,
Execute callback in pending stage */
uv__io_feed(handle->loop, &handle->io_watcher);
When the IO is finally closed (such as closing a TCP connection), the corresponding node will be removed from the pending queue. Because it has been closed, naturally there is no need to execute the callback.
void uv__io_close(uv_loop_t* loop, uv__io_t* w) {
uv__io_stop(loop,
w,
POLLIN | POLLOUT | UV__POLLRDHUP | UV__POLLPRI);
QUEUE_REMOVE(&w->pending_queue);
}
3.3 prepare, check, idle of event loop
prepare, check, and idle are relatively simple stages in the Libuv event loop, and their implementations are the same (see loop-watcher.c). This section only explains the prepare stage. We know that Libuv is divided into handle and request, and the tasks of the prepare stage belong to the handle type. This means that nodes in the prepare phase are executed every time the event loop occurs unless we explicitly remove them. Let's first see how to use it.
void prep_cb(uv_prepare_t *handle) {
printf("Prep callback\n");
}
int main() {
uv_prepare_t prep;
// Initialize a handle, uv_default_loop is the core structure of the event loop uv_prepare_init(uv_default_loop(), &prep);
// Register handle callback uv_prepare_start(&prep, prep_cb);
// Start the event loop uv_run(uv_default_loop(), UV_RUN_DEFAULT);
return 0;
}
When the main function is executed, Libuv will execute the callback prep_cb in the prepare phase. Let's analyze this process.
int uv_prepare_init(uv_loop_t* loop, uv_prepare_t* handle) {
uv__handle_init(loop, (uv_handle_t*)handle, UV_PREPARE);
handle->prepare_cb = NULL;
returnThe node is removed from the current queue QUEUE_REMOVE(q);
// Reinsert the original queue QUEUE_INSERT_TAIL(&loop->prepare_handles, q);
// Execute the callback function h->prepare_cb(h);
}
}
The logic of the uv__run_prepare function is very simple, but one key point is that after each node is executed, Libuv will re-insert the node into the queue, so the nodes in the prepare (including idle, check) stage will be executed in each round of the event loop. implement. Nodes such as timer, pending, and closing stages are one-time and will be removed from the queue after being executed. Let's review the test code at the beginning.
Because it sets the operating mode of Libuv to be the default mode. The prepare queue always has a handle node, so it will not exit. It will always execute the callback. So what if we want to quit? Or do not execute a node of the prepare queue. We just need to stop it once.
int uv_prepare_stop(uv_prepare_t* handle) {
if (!uv__is_active(handle)) return 0;
// Remove the handle from the prepare queue, but also mount it in handle_queue QUEUE_REMOVE(&handle->queue);
// Clear the active flag bit and subtract the active number of handles in the loop uv__handle_stop(handle);
return 0;
}
The stop function and the start function have opposite functions, which is the principle of the prepare, check, and idle phases in Node.js.
3.4 Poll IO of event loop
Poll IO is a very important stage of Libuv. File IO, network IO, signal processing, etc. are all processed in this stage, which is also the most complicated stage. The processing logic is in the uv**io_poll function of core.c. This function is more complicated, so we analyze it separately. Before starting to analyze Poll IO, let's take a look at some of the data structures related to it.
- IO observer uv**io_t. This structure is the core structure of the Poll IO stage. It mainly saves IO-related file descriptors, callbacks, events of interest and other information.
- watcher_queue watcher queue. All IO observers that need to be processed by Libuv are mounted in this queue, and Libuv will be processed one by one in the Poll IO stage.
Next we start to analyze the Poll IO stage. Look at the first paragraph of logic.
// If there is no IO observer, return directly if (loop->nfds == 0) {
assert(QUEUE_EMPTY(&loop->watcher_queue));
return;
}
// Traverse the IO watcher queue while (!QUEUE_EMPTY(&loop->watcher_queue)) {
// Take out the current head node q = QUEUE_HEAD(&loop->watcher_queue);
// Dequeue QUEUE_REMOVE(q);
// Initialize (reset) the front and back pointers of the node QUEUE_INIT(q);
// Successfully obtain the first address of the structure through the structure w = QUEUE_DATA(q, uv__io_t, watcher_queue);
// Set the current event of interest e.events = w->pevents;
/*
The fd field is used here, and after the event is triggered, the fd is used from the watches
The corresponding IO observer is found in the field, and there is no plan to use ptr to point to the IO observer*/
e.data.fd = w->fd;
// If w->events is 0 when initialized, add it, otherwise modify if (w->events == 0)
op = EPOLL_CTL_ADD;
else
op = EPOLL_CTL_MOD;
// Modify the data of epoll epoll_ctl(loop->backend_fd, op, w->fd, &e)
// Record the current state when added to epoll w->events = w->pevents;
}
The first step is to traverse the IO observer and modify the data of epoll. Then get ready to go into wait.
psigset = NULL;
if (loop->flags & UV_LOOP_BLOCK_SIGPROF) {
sigemptyset(&sigset);
sigaddset(&sigset, SIGPROF);
psigset = &sigset;
}
/*
http://man7.org/Linux/man-pages/man2/epoll_wait.2.html
pthread_sigmask(SIG_SETMASK, &sigmask, &origmask);
ready = epoll_wait(epfd, &events, maxevents, timeout);
pthread_sigmask(SIG_SETMASK, &origmask, NULL);
That is to shield the SIGPROF signal to prevent the SIGPROF signal from waking up epoll_wait, but there is no ready event*/
nfds = epoll_pwait(loop->backend_fd,
events,
ARRAY_SIZE(events),
timeout,
psigset);
// epoll may block, here you need to update the time of the event loop uv__update_time(loop) ```
epoll_wait may cause the main thread to block, so the current time needs to be updated after wait returns, otherwise the time difference will be relatively large when used, because Libuv will cache the current time value at the beginning of each round of time loop. Use it directly in other places, instead of getting it every time. Next, let's look at the processing after epoll returns (assuming an event is triggered).
// Save some data returned by epoll_wait, maybe_resize +2 when applying for space loop->watchers[loop->nwatchers] = (void*) events;
loop->watchers[loop->nwatchers + 1] = (void*) (uintptr_t) nfds;
for (i = 0; i < nfds; i++) {
// Triggered events and file descriptors pe = events + i;
fd = pe->data.fd;
// Get IO watchers according to fd, see the figure above w = loop->watchers[fd];
// will be deleted in other callbacks, then delete from epoll if (w == NULL) {
epoll_ctl(loop->backend_fd, EPOLL_CTL_DEL, fd, pe);
continue;
}
if (pe->events != 0) {
/*
The event of interest to the IO observer for signal handling is fired,
That is, a signal occurs.
*/
if (w == &loop->signal_io_watcher)
have_signals =
}
After doing different processing according to different handles, then execute uv__make_close_pending to add nodes to the close queue.
// The head insertion method is inserted into the closing queue and executed during the closing phase void uv__make_close_pending(uv_handle_t* handle) {
handle->next_closing = handle->loop->closing_handles;
handle->loop->closing_handles = handle;
}
It is then processed one by one in the close phase. Let's take a look at the processing logic of the close phase
// Callback for executing closing phase static void uv\_\_run_closing_handles(uv_loop_t* loop) {
uv_handle_t* p;
uv_handle_t\* q;
p = loop->closing_handles;
loop->closing_handles = NULL;
while (p) {
q = p->next_closing;
uv__finish_close(p);
p = q;
}
}
// Execute the callback of the closing phase static void uv__finish_close(uv_handle_t* handle) {
handle->flags |= UV_HANDLE_CLOSED;
...
uv__handle_unref(handle);
// remove QUEUE_REMOVE(&handle->handle_queue) from handle queue;
if (handle->close_cb) {
handle->close_cb(handle);
}
}
uv__run_closing_handles will execute the callback of each task node one by one.
3.6 Controlling the event loop
Libuv uses the uv__loop_alive function to determine whether the event loop needs to continue to execute. Let's look at the definition of this function.
static int uv__loop_alive(const uv_loop_t* loop) {
return uv__has_active_handles(loop) ||
uv__has_active_reqs(loop) ||
loop->closing_handles != NULL;
}
Why is there a judgment of closing_handle? Judging from the code of uv_run, after the close phase is executed, uv_loop_alive will be executed immediately. Normally, the queue in the close phase is empty, but if we add a new node to the close queue in the close callback, and the node It will not be executed in the close phase of this round, which will cause the close phase to be executed, but there are still nodes in the close queue. If it exits directly, the corresponding callback cannot be executed. We see three cases where Libuv considers the event loop to be alive. If we control these three conditions, we can control the exit of the event loop. Let us understand this process with an example.
const timeout = setTimeout(() => {
console.log('never console')
}, 5000);
timeout.unref();
In the above code, the callback of setTimeout will not be executed. Unless the timeout period is very short, it will expire when the first round of event loop is short, otherwise after the first round of event loop, due to the influence of unref, the event loop exits directly. Unref affects the handle condition. The event loop code is as follows.
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
uv__run_timers(loop);
// ...
// uv__loop_alive returns false and jumps out of the while, thereby exiting the event loop r = uv__loop_alive(loop);
}
Thread Pool
Libuv is a single-threaded event-driven asynchronous IO library. For blocking or time-consuming operations, if executed in the main loop of Libuv, it will block the execution of subsequent tasks,
so Libuv maintains a Thread pool, which is responsible for processing time-consuming or blocking operations in Libuv, such as file IO, DNS, and custom time-consuming tasks. The location of the thread pool in the Libuv architecture is shown in Figure 4-1.
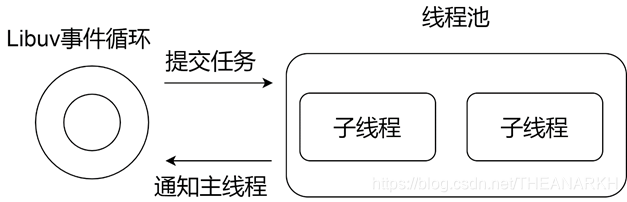
The main thread of Libuv submits the task to the thread pool through the interface provided by the thread pool, and then immediately returns to the event loop to continue execution. The thread pool maintains a task queue, and multiple sub-threads will pick off the task node from it for execution. After the thread has completed the task, it will notify the main thread, and the main thread will execute the corresponding callback in the Poll IO stage of the event loop. Let's take a look at the implementation of the thread pool in Libuv.
4.1 Communication between main thread and sub-thread
The communication between Libuv sub-thread and main thread is implemented using the uv_async_t structure.
Libuv uses the loop->async_handles queue to record all uv_async_t structures, and uses loop->async_io_watcher as the IO watcher of all uv_async_t structures, that is, all handles on the loop->async_handles queue share the async_io_watcher IO watcher.
When inserting a uv_async_t structure into the async_handle queue for the first time, the IO observer will be initialized. If an async_handle is registered again, only one node will be inserted into the loop->async_handle queue and handle queue, and an IO observer will not be added. When the task corresponding to the uv_async_t structure is completed, the child thread will set the IO observer to be readable.
Libuv handles IO observers during the Poll IO phase of the event loop. Let's take a look at the use of uv_async_t in Libuv.
4.1.1 Initialization Before using uv_async_t, you need to execute uv_async_init for initialization.
int uv_async_init(uv_loop_t* loop,
uv_async_t* handle,
uv_async_cb async_cb) {
int err;
// Register an observer io with Libuv
err = uv__async_start(loop);
if (err)
return err;
// Set relevant fields and insert a handle to Libuv
uv__handle_init(loop, (uv_handle_t*)handle, UV_ASYNC);
// set callback handle->async_cb = async_cb;
// Initialize the flag field, 0 means no task is completed handle->pending = 0;
// Insert uv_async_t into the async_handle queue QUEUE_INSERT_TAIL(&loop->async_handles, &handle->queue);
uv__handle_start(handle);
return 0;
}
The uv_async_init function mainly initializes some fields of the structure uv_async_t, and then executes QUEUE_INSERT_TAIL to add a node to Libuv's async_handles queue. We see that there is also a uv *async_start function. Let's look at the implementation of uv *async_start.
static int uv__async_start(uv_loop_t* loop) {
int pipefd[2];
int err;
// uv__async_start is executed only once, if there is fd, it is not necessary to execute if (loop->async_io_watcher.fd != -1)
return 0;
// Get an fd for inter-process communication (Linux's eventfd mechanism)
err = uv__async_eventfd();
/*
If it succeeds, save the fd. If it fails, it means that eventfd is not supported.
Then use pipe communication as inter-process communication */
if (err >= 0) {
pipefd[0] = err;
pipefd[1] = -1;
}
else if (err == UV_ENOSYS) {
// If eventfd is not supported, use anonymous pipe err = uv__make_pipe(pipefd, UV__F_NONBLOCK);
#if defined(__Linux__)
if (err == 0) {
char buf[32];
int fd;
snprintf(buf, sizeof(buf), "/proc/self/fd/%d", pipefd[0]); // Reading and writing to pipes can be achieved through a fd, advanced usage fd = uv__open_cloexec(buf, O_RDWR );
if (fd >= 0) {
// close the old uv__close(pipefd[0]);
uv__close(pipefd[1]);// assign new pipefd[0] = fd;
pipefd[1] = fd;
}
}
#endif
}
// err greater than or equal to 0 means that the read and write ends of the communication are obtained if (err < 0)
return err;
/*
Initialize IO watcher async_io_watcher,
Save the read file descriptor to the IO observer */
uv__io_init(&loop->async_io_watcher, uv__async_io, pipefd[0]);
// Register the IO watcher in the loop, and register the interested event POLLIN, waiting for the read uv__io_start(loop, &loop->async_io_watcher, POLLIN);
// Save the write file descriptor loop->async_wfd = pipefd[1];
return 0;
}
uv_async_start will only be executed once, and the timing is when uv_async_init is executed for the first time. The main logic of uv**async_start is as follows: 1 Obtain the communication descriptor (generate a communication fd through eventfd (acting as both read and write ends) or the pipeline generates two fds for inter-thread communication representing the read end and the write end). 2 Encapsulate interesting events and callbacks to IO observers and then append them to the watcher_queue queue. In the Poll IO stage, Libuv will be registered in epoll.
If there are tasks completed, the callback will also be executed in the Poll IO stage. 3 Save the write side descriptor. When the task is completed, the main thread is notified through the write-side fd. We see that there is a lot of logic in the uv**async_start function to obtain the communication file descriptor. In general, it is to complete the function of communication between the two ends. After initializing the async structure, the Libuv structure is shown in Figure 4-2.

4.1.2 After informing the main thread to initialize the async structure
if the task corresponding to the async structure is completed, the main thread will be notified, and the sub-thread will mark the task completion by setting the pending of the handle to 1, and then write to the pipeline The terminal writes a flag to notify the main thread that a task has been completed.
int uv_async_send(uv_async_t* handle) {
/* Do a cheap read first. */
if (ACCESS_ONCE(int, handle->pending) != 0)
return 0;
/*
If pending is 0, set it to 1, return 0, if it is 1, return 1,
So if the function is called multiple times, it will be merged */
if (cmpxchgi(&handle->pending, 0, 1) == 0)
uv__async_send(handle->loop);
return 0;
}
static void uv__async_send(uv_loop_t* loop) {
const void* buf;
ssize_t len;
int fd;
int r;
buf = "";
len = 1;
fd = loop->async_wfd;
#if defined(__Linux__)
// Indicates that eventfd is used instead of a pipe, and the read and write ends of eventfd correspond to the same fd
if (fd == -1) {
static const uint64_t val = 1;
buf = &val;
len = sizeof(val);
// see uv__async_start
fd = loop->async_io_watcher.fd; /* eventfd */
}
#endif
// notify the read end do
r = write(fd, buf, len);
while (r == -1 && errno == EINTR);
if (r == len)
return;
if (r == -1)
if (errno == EAGAIN || errno == EWOULDBLOCK)
return;
abort();
}
uv_async_send first gets the fd corresponding to the write end, and then calls the write function. At this time, data is written to the write end of the pipeline, and the task is marked as complete. Where there is writing, there must be reading. The logic for reading is implemented in uv *io_poll. The uv *io_poll function is the function executed in the Poll IO stage in Libuv. In uv *io_poll, the pipeline will be found to be readable, and then the corresponding callback uv *async_io will be executed.
4.1.3 Main thread processing callback
static void uv__async_io(uv_loop_t* loop,
uv__io_t* w,
unsigned int events) {
char buf[1024];
ssize_tr;
QUEUE queue;
QUEUE* q;
uv_async_t* h;
for (;;) {
// consume all data r = read(w->fd, buf, sizeof(buf));
// If the data size is greater than the buf length (1024), continue to consume if (r == sizeof(buf))
continue;
// After successful consumption, jump out of the logic of consumption if (r != -1)
break;
// read busy if (errno == EAGAIN || errno == EWOULDBLOCK)
break;
// read is interrupted, continue reading if (errno == EINTR)
continue;
abort();
}
// Move all nodes in the async_handles queue to the queue variable QUEUE_MOVE(&loop->async_handles, &queue);
while (!QUEUE_EMPTY(&queue)) {
// Take out nodes one by one q = QUEUE_HEAD(&queue);
// Get the first address of the structure according to the structure field h = QUEUE_DATA(q, uv_async_t, queue);
// remove the node from the queue QUEUE_REMOVE(q);
// Reinsert the async_handles queue and wait for the next event QUEUE_INSERT_TAIL(&loop->async_handles, q);
/*
Compare the first parameter with the second parameter, if equal,
Then write the third parameter to the first parameter, return the value of the second parameter,
If not equal, return the value of the first argument.
*/
/*
Determine which async is triggered. pending is set to 1 in uv_async_send,
If pending is equal to 1, clear 0 and return 1. If pending is equal to 0, return 0
*/
if (cmpxchgi(&h->pending, 1, 0) ==Task. Later we will analyze the logic of the worker.
4.2.2 Submitting tasks to the thread pool
After understanding the initialization of the thread pool, let's take a look at how to submit tasks to the thread pool
// Submit a task to the thread pool void uv__work_submit(uv_loop_t* loop,
struct uv__work* w,
enum uv__work_kind kind,
void (*work)(struct uv__work* w),
void (*done)(struct uv__work* w, int status)){
/*
It is guaranteed that the thread has been initialized and executed only once, so the thread pool is only initialized when the first task is submitted, init_once -> init_threads
*/
uv_once(&once, init_once);
w->loop = loop;
w->work = work;
w->done = done;
post(&w->wq, kind);
}
Here, the business-related functions and the callback function after the task is completed are encapsulated into the uv *work structure. The uv *work structure is defined as follows.
struct uv__work {
void (*work)(struct uv__work *w);
void (*done)(struct uv__work *w, int status);
struct uv_loop_s* loop;
void* wq[2];
};
Then call the post function to add a new task to the queue of the thread pool. Libuv divides tasks into three types, slow IO (DNS resolution), fast IO (file operations), CPU-intensive, etc. Kind is the type of task. Let's look at the post function next.
static void post(QUEUE* q, enum uv__work_kind kind) {
// Lock access to the task queue, because this queue is shared by the thread pool uv_mutex_lock(&mutex);
// type is slow IO
if (kind == UV__WORK_SLOW_IO) {
/*
Insert the queue corresponding to slow IO. This version of Libuv divides tasks into several types.
For tasks of slow IO type, Libuv inserts a special node run_slow_work_message into the task queue, and then uses slow_io_pending_wq to maintain a slow IO
The queue of tasks, when the node run_slow_work_message is processed,
Libuv will take out task nodes one by one from the slow_io_pending_wq queue for execution.
*/
QUEUE_INSERT_TAIL(&slow_io_pending_wq, q);
/*
When there is a slow IO task, you need to insert a message node run_slow_work_message into the main queue wq, indicating that there is a slow IO task, so if run_slow_work_message is empty, it means that the main queue has not been inserted. q = &run_slow_work_message; needs to be assigned, and then run_slow_work_message is inserted into the main queue. if run_slow_work_message
If it is not empty, it means that it has been inserted into the task queue of the thread pool. Unlock and go straight back.
*/
if (!QUEUE_EMPTY(&run_slow_work_message)) {
uv_mutex_unlock(&mutex);
return;
}
// Indicates that run_slow_work_message has not been inserted into the queue, ready to be inserted into the queue q = &run_slow_work_message;
}
// Insert the node into the main queue, which may be a slow IO message node or a general task QUEUE_INSERT_TAIL(&wq, q);
/*
Wake it up when there is an idle thread, if everyone is busy,
Then wait until it is busy and then re-determine whether there are new tasks */
if (idle_threads > 0)
uv_cond_signal(&cond);
// After operating the queue, unlock uv_mutex_unlock(&mutex);
}
This is the producer logic of the thread pool in Libuv. The architecture of the task queue is shown in Figure 4-3.
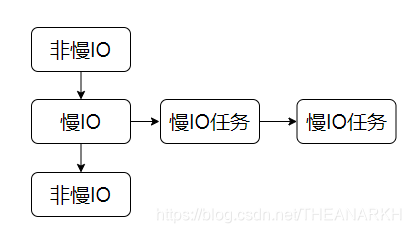
In addition to the above mentioned, Libuv also provides another way to produce tasks, the uv_queue_work function, which only submits CPU-intensive tasks (used in Node.js's crypto module). Let's look at the implementation of uv_queue_work.
int uv_queue_work(uv_loop_t* loop,
uv_work_t* req,
uv_work_cb work_cb,
uv_after_work_cb after_work_cb) {
if (work_cb == NULL)
return UV_EINVAL;
uv__req_init(loop, req, UV_WORK);
req->loop = loop;
req->work_cb = work_cb;
req->after_work_cb = after_work_cb;
uv__work_submit(loop,
&req->work_req,
UV__WORK_CPU,
uv__queue_work,
uv__queue_done);
return 0;
}
The uv_queue_work function actually doesn't have much logic. It saves the user's work function and calls it back into the request. Then encapsulate uv *queue_work and uv *queue_done into uv**work, and then submit tasks to the thread pool. So when this task is executed. It will execute the work function uv *queue_work.
static void uv__queue_work(struct uv__work* w) {
// Get the structure address through a field of the structure uv_work_t* req = container_of(w, uv_work_t, work_req);
req->work_cb(req);
}
We see that uv *queue_work actually encapsulates user-defined task functions. At this time, we can guess that uv *queue_done is just a simple encapsulation of the user's callback, that is, it will execute the user's callback.
4.2.3 Processing tasks After we submit the task
the thread must be processed naturally. When we initialized the thread pool, we analyzed that the worker function is responsible for processing the task. Let's take a look at the logic of the worker function.
static void worker(void* arg) {
struct uv__work* w;
QUEUE* q;
int is_slow_work;
// Thread started successfully uv_sem_post((uv_sem_t*) arg);
arg = NULL;
// lock mutex access task queue uv_mutex_lock(&mutex);
for (;;) {
Manage slow IO tasks is_slow_work = 1;
/*
The number of slow IO tasks being processed is accumulated, which is used by other threads to judge whether the number of slow IO tasks reaches the threshold. slow_io_work_running is a variable shared by multiple threads*/
slow_io_work_running++;
// Take off a slow IO task q = QUEUE_HEAD(&slow_io_pending_wq);
// remove QUEUE_REMOVE(q) from slow IO queue;
QUEUE_INIT(q);
/*
After taking out a task, if there is still a slow IO task, the slow IO marked node will be re-queued, indicating that there is still a slow IO task, because the marked node is dequeued above */
if (!QUEUE_EMPTY(&slow_io_pending_wq)) {
QUEUE_INSERT_TAIL(&wq, &run_slow_work_message);
// wake it up if there is an idle thread, because there are still tasks to process if (idle_threads > 0)
uv_cond_signal(&cond);
}
}
// No need to operate the queue, release the lock as soon as possible uv_mutex_unlock(&mutex);
// q is slow IO or general task w = QUEUE_DATA(q, struct uv__work, wq);
// The task function for executing the business, which generally blocks w->work(w);
// Prepare the task completion queue for operating loop, lock uv_mutex_lock(&w->loop->wq_mutex);
// Blanking indicates that the execution is complete, see cancel logic w->work = NULL;
/*
After executing the task, insert it into the wq queue of the loop, and execute the node of the queue when uv__work_done */
QUEUE_INSERT_TAIL(&w->loop->wq, &w->wq);
// Notify loop's wq_async node uv_async_send(&w->loop->wq_async);
uv_mutex_unlock(&w->loop->wq_mutex);
// Lock the next round of operation task queue uv_mutex_lock(&mutex);
/*
After executing the slow IO task, record the number of slow IOs being executed and decrease the variable by 1.
The above lock ensures exclusive access to this variable */
if (is_slow_work) {
slow_io_work_running--;
}
}
}
We see that the logic of consumers seems to be more complicated. For tasks of slow IO type, Libuv limits the number of threads that process slow IO tasks, so as to avoid tasks that take less time from being processed. The rest of the logic is similar to the general thread pool, that is, mutual exclusive access to the task queue, then take out the node for execution, and notify the main thread after execution. The structure is shown in Figure 4-4.

4.2.4 Notify the main thread that after the thread has completed the task
it will not directly execute the user callback, but notify the main thread, which will be processed uniformly by the main thread. For the complex problems caused by threads, let's take a look at the logic of this piece. Everything starts from the initialization of Libuv
uv_default_loop();->uv_loop_init();->uv_async_init(loop, &loop->wq_async, uv\_\_work_done);
We have just analyzed the communication mechanism between the main thread and the sub-thread. wq_async is the async handle used for the communication between the sub-thread and the main thread in the thread pool, and its corresponding callback is uvwork_done. So when the thread task of a thread pool is completed, set loop->wq_async.pending = 1 through uv_async_send(&w->loop->wq_async), and then notify the IO observer, Libuv will execute the corresponding handle in the Poll IO stage Call back the uvwork_done function. So let's look at the logic of this function.
void uv__work_done(uv_async_t* handle) {
struct uv__work* w;
uv_loop_t* loop;
QUEUE* q;
QUEUE wq;
int err;
// Get the first address of the structure through the structure field loop = container_of(handle, uv_loop_t, wq_async);
// Prepare to process the queue, lock uv_mutex_lock(&loop->wq_mutex);
/*
loop->wq is the completed task queue. Move all the nodes of the loop->wq queue to the wp variable, so that the lock can be released as soon as possible*/
QUEUE_MOVE(&loop->wq, &wq);
// No need to use, unlock uv_mutex_unlock(&loop->wq_mutex);
// The node of the wq queue is inserted from the child thread while (!QUEUE_EMPTY(&wq)) {
q = QUEUE_HEAD(&wq);
QUEUE_REMOVE(q);
w = container_of(q, struct uv__work, wq);
// equal to uv__canceled means the task has been cancelled err = (w->work == uv__cancelled) ? UV_ECANCELED : 0;
// Execute the callback w->done(w, err);
}
}
The logic of this function is relatively simple. It processes the completed task nodes one by one and executes the callback. In Node.js, the callback here is the C++ layer, and then to the JS layer. The structure diagram is shown in Figure 4-5.
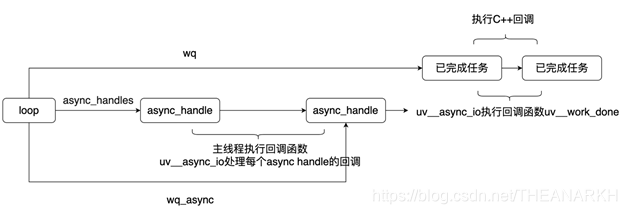
4.2.5 Cancellation of tasks In the design of the thread pool
canceling tasks is a relatively important capability, because some time-consuming or blocking operations are performed in threads. If a task can be canceled in time, it will reduce the A lot of unnecessary processing. However, in the Libuv implementation, the task can only be canceled when the task is still in the waiting queue.
If a task is being processed by a thread, it cannot be canceled. Let's first look at how Libuv implements cancellation tasks. Libuv provides the uv__work_cancel function to support the user to cancel the submitted task. Let's look at its logic.
static int uv__work_cancel(uv_loop_t* loop, uv_req_t* req, struct uv__work* w) {
int cancelled;
// lock, in order to remove the node from the queue uv_mutex_lock(&mutex);
// lock, in order to determine whether w->wq is empty uv_mutex_lock(&w->loop->wq_mutex);
/*
cancelled is true, indicating that the task is still in the thread pool queue waiting to be processed 1. After processing, w->work == NULL
2 During processing, QUEUE_EMPTY(&w->wq) is true, because
Streams
mplementation of Libuv stream occupies a lot of space in Libuv and is a very core logic. The essence of a stream is to encapsulate operations on file descriptors, such as reading, writing, connecting, and listening. Let's first look at the data structure. The stream is represented by uv_stream_s in Libuv, which is inherited from uv_handle_s.
struct uv_stream_s {
// Field void* data of uv_handle_s;
// belongs to the event loop uv_loop_t* loop;
// handle type uv_handle_type type;
// Callback when the handle is closed uv_close_cb close_cb;
// handle queue for inserting event loop void* handle_queue[2];
union {
int fd;
void* reserved[4];
} u;
// used to insert the closing phase of the event loop uv_handle_t* next_closing;
// various flags unsigned int flags;
// stream extended fields/*
the size in bytes the user writes to the stream, the stream buffers the user's input,
Then wait until it is writable to perform the real write */
size_t write_queue_size;
// The function of allocating memory, the memory is defined by the user, used to save the read data uv_alloc_cb alloc_cb;
// read callback uv_read_cb read_cb;
// The structure corresponding to the connection request uv_connect_t *connect_req;
/*
When the write end is closed, the cached data is sent,
Execute the callback of shutdown_req (shutdown_req is assigned when uv_shutdown)
*/
uv_shutdown_t *shutdown_req;
/*
The IO observer corresponding to the stream */
uv__io_t io_watcher;
// Cache the data to be written, this field is used to insert the queue void* write_queue[2];
// The queue to which data writing has been completed, this field is used to insert the queue void* write_completed_queue[2];
// After a connection arrives and the three-way handshake is completed, the callback uv_connection_cb connection_cb is executed;
// Error code when operating stream int delayed_error;
// The file description corresponding to the communication socket returned by accept int accepted_fd;
// Same as above, when used for IPC, cache multiple passed file descriptors void* queued_fds;
}
In the implementation of the stream, the core field is the IO observer, and the rest of the fields are related to the nature of the stream. The IO observer encapsulates the file descriptor corresponding to the stream and the callback when the file descriptor event is triggered. For example, read a stream, write a stream, close a stream, connect a stream, listen to a stream, there are corresponding fields in uv_stream_s to support. But it is essentially driven by IO observers.
-
To read a stream, that is, when the readable event of the file descriptor in the IO observer is triggered, the user's read callback is executed.
-
Write a stream, first write the data to the stream, wait until the file descriptor writable event in the IO observer is triggered, execute the real write, and execute the user's write end callback.
-
To close a stream, that is, when the file descriptor writable event in the IO observer is triggered, the write end of the closed stream will be executed. If there is still data in the stream that has not been written, it will be written (such as sending) before the close operation is performed, and then the user's callback will be executed.
-
Connection streams, such as connecting to a server as a client. That is, when the file descriptor readable event in the IO observer is triggered (for example, the establishment of the three-way handshake is successful), the user's callback is executed.
-
Listening to the stream, that is, when the file descriptor readable event in the IO observer is triggered (for example, there is a connection that completes the three-way handshake), the user's callback is executed.
Let's take a look at the specific implementation of the stream ## 5.1 Initializing the stream Before using uv_stream_t, it needs to be initialized first. Let's take a look at how to initialize a stream.
void uv__stream_init(uv_loop_t* loop,
uv_stream_t* stream,
uv_handle_type type) {
int err;
// Record the type of handle uv__handle_init(loop, (uv_handle_t*)stream, type);
stream->read_cb = NULL;
stream->alloc_cb = NULL;
stream->close_cb = NULL;
stream->connection_cb = NULL;
stream->connect_req = NULL;
stream->shutdown_req = NULL;
stream->accepted_fd = -1;
stream->queued_fds = NULL;
stream->delayed_error = 0;
QUEUE_INIT(&stream->write_queue);
QUEUE_INIT(&stream->write_completed_queue);
stream->write_queue_size = 0;
/*
Initialize the IO watcher, record the file descriptor (there is none here, so it is -1) and the callback uv_stream_io on the io_watcher. When the fd event is triggered, it will be handled by the uv_stream_io function, but there are also special cases (will be discussed below). )
*/
uv__io_init(&stream->io_watcher, uv__stream_io, -1);
}
The logic of initializing a stream is very simple and clear, which is to initialize the relevant fields. It should be noted that when initializing the IO observer, the set processing function is uv__stream_io, and we will analyze the specific logic of this function later.
5.2 Open stream
int uv__stream_open(uv_stream_t* stream, int fd, int flags) {
// If the fd has not been set or the same fd is set, continue, otherwise return UV_EBUSY
if (!(stream->io_watcher.fd == -1 ||
stream->io_watcher.fd == fd))
return UV_EBUSY;
// Set the flags of the stream stream->flags |= flags;
// If it is a TCP stream, you can set the following properties if (stream->type == UV_TCP) {
// Turn off the nagle algorithm if ((stream->flags & UV_HANDLE_TCP_NODELAY) &&
uv__tcp_nodelay(fd, 1))
return UV__ERR(errno);
/*
Enable keepalive mechanism*/
if ((stream->flags & UV_HANDLE_TCP_KEEPALIVE) &&
uv__tcp_keepalive(fd, 1, 60)) {
return UV__ERR(errno);
}
}
/*
Save the file descriptor corresponding to the socket to the IO observer, and Libuv will monitor the file descriptor in the Poll IO stage */
stream->io_watcher.fd = fd;
return 0;
}
Opening a stream is essentially associating a file descriptor with the stream. Subsequent operations are based on this file descriptor, as well as some attribute settings.
5.3 Reading Streams After we execute uv_read_start on a stream
the stream's data (if any) will flow continuously to the caller through the read_cb callback.
int uv_read_start(uv_stream_t* stream,
uv_alloc_cb alloc_cb,
uv_read_cb read_cb) {
// stream is closed, can't read if (stream->flags & UV_HANDLE_CLOSING)
return UV_EINVAL;
// The stream is unreadable, indicating that it may be a write-only stream if (!(stream->flags & UV_HANDLE_READABLE))
return -ENOTCONN;
// Flag reading stream->flags |= UV_HANDLE_READING;
// Record the read callback, this callback will be executed when there is data stream->read_cb = read_cb;
// Allocating memory function to store read data stream->alloc_cb = alloc_cb;
// Register waiting for read event uv__io_start(stream->loop, &stream->io_watcher, POLLIN);
// Activate handle, if there is an activated handle, the event loop will not exit uv__handle_start(stream);
return 0;
}
Executing uv_read_start essentially registers a waiting read event in epoll for the file descriptor corresponding to the stream, and records the corresponding context, such as the read callback function and the function of allocating memory. Then mark it as doing a read operation. When the read event is triggered, the read callback will be executed. In addition to reading data, there is also a read operation that stops reading. The corresponding function is uv_read_stop.
int uv_read_stop(uv_stream_t* stream) {
// Whether a read operation is being performed, if not, there is no need to stop if (!(stream->flags & UV_HANDLE_READING))
return 0;
// Clear the flags being read stream->flags &= ~UV_HANDLE_READING;
// Cancel waiting for read event uv__io_stop(stream->loop, &stream->io_watcher, POLLIN);
// Not interested in writing events, stop handle. Allow event loop to exit if (!uv__io_active(&stream->io_watcher, POLLOUT))
uv__handle_stop(stream);
stream->read_cb = NULL;
stream->alloc_cb = NULL;
return 0;
}
There is also a helper function that determines whether the stream has the readable property set.
int uv_is_readable(const uv_stream_t* stream) {
return !!(stream->flags & UV_HANDLE_READABLE);
}
The above function just registers and deregisters the read event. If the read event is triggered, we also need to read the data ourselves. Let's take a look at the real read logic
static void uv**read(uv_stream_t\* stream) {
uv_buf_t buf;
ssize_t nread;
struct msghdr msg;
char cmsg_space[CMSG_SPACE(UV**CMSG*FD_SIZE)];
int count;
int err;
int is_ipc;
// clear read part flag stream->flags &= ~UV_STREAM_READ_PARTIAL;
count = 32;
// Streams are Unix domain types and are used for IPC, Unix domains are not necessarily used for IPC,
// Used as IPC to support passing file descriptors \_/
is_ipc = stream->type == UV_NAMED_PIPE &&
((uv_pipe_t\*) //img-blog.csdnimg.cn/20210420235737186.png)
Let's take a look at the structure after fork as shown in Figure 5-2.
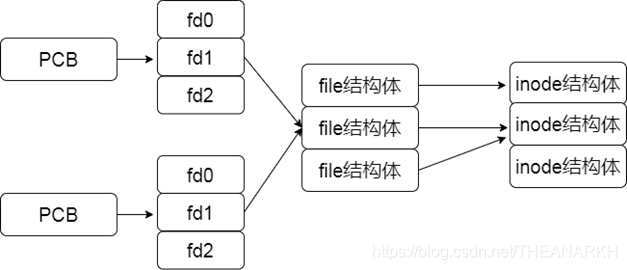
If the parent process or the child process creates a new file descriptor after fork, the parent and child processes cannot share it. Suppose the parent process wants to pass a file descriptor to the child process, what should we do? According to the relationship between process and file descriptor.
The thing to do when passing the file descriptor is not only to create a new fd in the child process, but also to establish the association of fd->file->inode, but we don't need to pay attention to these, because the operating system handles it for us, We just need to send the file descriptor we want to pass to the other end of the Unix domain via sendmsg.
The other end of the Unix domain can then read the file descriptor from the data via recvmsg. Then use the uv__stream_recv_cmsg function to save the file descriptor parsed from the data.
static int uv__stream_recv_cmsg(uv_stream_t* stream,
struct msghdr* msg) {
struct cmsghdr* cmsg;
// iterate over msg
for (cmsg = CMSG_FIRSTHDR(msg);
cmsg != NULL;
cmsg = CMSG_NXTHDR(msg, cmsg)) {
char* start;
char* end;
int err;
void* pv;
int* pi;
unsigned int i;
unsigned int count;
pv = CMSG_DATA(cmsg);
pi = pv;
start = (char*) cmsg;
end = (char*) cmsg + cmsg->cmsg_len;
count = 0;
while (start + CMSG_LEN(count * sizeof(*pi)) < end)
count++;
for (i = 0; i < count; i++) {
/*
accepted_fd represents the currently pending file descriptor,
If there is already a value, the remaining descriptors are queued through uv__stream_queue_fd If there is no value, it will be assigned first */
if (stream->accepted_fd != -1) {
err = uv__stream_queue_fd(stream, pi[i]);
} else {
stream->accepted_fd = pi[i];
}
}
}
return 0;
}
uv *stream_recv_cmsg will parse out the file descriptors from the data and store them in the stream.
The first file descriptor is stored in accepted_fd, and the rest are processed by uv *stream_queue_fd.
struct uv__stream_queued_fds_s {
unsigned int size;
unsigned int offset;
int fds[1];
};
static int uv__stream_queue_fd(uv_stream_t* stream, int fd) {
uv__stream_queued_fds_t* queued_fds;
unsigned int queue_size;
// original memory queued_fds = stream->queued_fds;
// no memory, allocate if (queued_fds == NULL) {
// default 8 queue_size = 8;
/*
One metadata memory + multiple fd memory (prefixed with * represents the memory size occupied by the type of the dereferenced value,
Minus one because uv__stream_queued_fds_t
The struct itself has a space)
*/
queued_fds = uv__malloc((queue_size - 1) *
sizeof(*queued_fds->fds) +
sizeof(*queued_fds));
if (queued_fds == NULL)
return UV_ENOMEM;
// Capacity queued_fds->size = queue_size;
// The number of used queued_fds->offset = 0;
// Point to available memory stream->queued_fds = queued_fds;
// The previous memory is used up, expand the capacity } else if (queued_fds->size == queued_fds->offset) {
// Add 8 each time queue_size = queued_fds->size + 8;
queued_fds = uv__realloc(queued_fds,
(queue_size - 1) * sizeof(*queued_fds->fds) + sizeof(*queued_fds));
if (queued_fds == NULL)
return UV_ENOMEM;
// Update capacity size queued_fds->size = queue_size;
// save new memory stream->queued_fds = queued_fds;
}
/* Put fd in a queue */
// save fd
queued_fds->fds[queued_fds->offset++] = fd;
return 0;
}
The memory structure is shown in Figure 5-3.
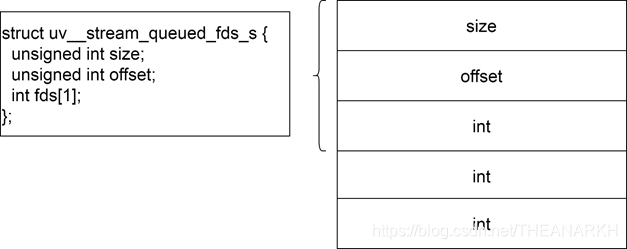
Finally, let's look at the processing after reading,
static void uv__stream_eof(uv_stream_t* stream,
const uv_buf_t* buf) {
// Mark the read end stream->flags |= UV_STREAM_READ_EOF;
// Log out waiting for readable events uv__io_stop(stream->loop, &stream->io_watcher, POLLIN);
// If there is no registration to wait for a writable event, stop the handle, otherwise it will affect the exit of the event loop if (!uv__io_active(&stream->io_watcher, POLLOUT))
uv__handle_stop(stream);
uv__stream_osx_interrupt_select(stream);
// Execute read callback stream->read_cb(stream, UV_EOF, buf);
// clear reading flag stream->flags &= ~UV_STREAM_READING;
}
We see that when the stream ends, first log out and wait for a readable event, and then notify the upper layer through a callback.
5.4 Write stream
We can write data to the stream by executing uv_write on the stream.
int uv_write(
/*
return;
q = QUEUE_HEAD(&stream->write_queue);
req = QUEUE_DATA(q, uv_write_t, queue);
// where to start writing iov = (struct iovec*) &(req->bufs[req->write_index]);
// How many are left unwritten iovcnt = req->nbufs - req->write_index;
// how many iovmax can write = uv__getiovmax();
// take the minimum value if (iovcnt > iovmax)
iovcnt = iovmax;
// Need to pass file descriptor if (req->send_handle) {
int fd_to_send;
struct msghdr msg;
struct cmsghdr *cmsg;
union {
char data[64];
struct cmsghdr alias;
} scratch;
if (uv__is_closing(req->send_handle)) {
err = -EBADF;
goto error;
}
// File descriptor to be sent fd_to_send = uv__handle_fd((uv_handle_t*) req->send_handle);
memset(&scratch, 0, sizeof(scratch));
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = iovcnt;
msg.msg_flags = 0;
msg.msg_control = &scratch.alias;
msg.msg_controllen = CMSG_SPACE(sizeof(fd_to_send));
cmsg = CMSG_FIRSTHDR(&msg);
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_type = SCM_RIGHTS;
cmsg->cmsg_len = CMSG_LEN(sizeof(fd_to_send));
{
void* pv = CMSG_DATA(cmsg);
int* pi = pv;
*pi = fd_to_send;
}
do {
// Send the file descriptor using the sendmsg function n = sendmsg(uv__stream_fd(stream), &msg, 0);
}
while (n == -1 && errno == EINTR);
} else {
do {
// write one or write batches if (iovcnt == 1) {
n = write(uv__stream_fd(stream),
iov[0].iov_base,
iov[0].iov_len);
} else {
n = writev(uv__stream_fd(stream), iov, iovcnt);
}
}
while (n == -1 && errno == EINTR);
}
// write failed if (n < 0) {
/*
If it is not busy writing, an error will be reported.
else if the synchronous write flag is set, keep trying to write */
if (errno != EAGAIN &&
errno != EWOULDBLOCK &&
errno != ENOBUFS) {
err = -errno;
goto error;
} else if (stream->flags & UV_STREAM_BLOCKING) {
/* If this is a blocking stream, try again. */
goto start;
}
} else {
// write successfully while (n >= 0) {
// Current buf first address uv_buf_t* buf = &(req->bufs[req->write_index]);
// The data length of the current buf size_t len = buf->len;
// Less than that means the current buf has not been written yet (has not been consumed)
if ((size_t)n < len) {
// Update the first address to be written buf->base += n;
// Update the length of the data to be written buf->len -= n;
/*
Update the length of the queue to be written, which is the total length of the data to be written, equal to the sum of multiple bufs */
stream->write_queue_size -= n;
n = 0;
/*
If you haven't finished writing, and set up synchronous writing, continue to try to write,
Otherwise, exit and register the event to be written */
if (stream->flags & UV_STREAM_BLOCKING) {
goto start;
} else {
break;
}
} else {
/*
The data of the current buf is all written, then update the first address of the data to be written, that is, the next buf, because the current buf is finished */
req->write_index++;
// update n for the calculation of the next loop n -= len;
// Update the length of the queue to be written stream->write_queue_size -= len;
/*
It is equal to the last buf, indicating that the data to be written in the queue is all written */
if (req->write_index == req->nbufs) {
/*
Release the memory corresponding to buf, insert the request into the write completion queue, and prepare to trigger the write completion callback */
uv__write_req_finish(req);
return;
}
}
}
}
/*
The writing is successful, but it is not finished yet, register the event to be written,
Continue writing while waiting for writable */
uv__io_start(stream->loop, &stream->io_watcher, POLLOUT);
uv__stream_osx_interrupt_select(stream);
return;
// write error error:
// log errors req->error = err;
/*
free memory, discard data, insert write completion queue,
Insert the IO observer into the pending queue and wait for the pending phase to execute the callback */
uv__write_req_finish(req);
//eq,
uv_stream_t* stream,
uv_shutdown_cb cb) {
// Initialize a close request, the associated handle is stream
uv__req_init(stream->loop, req, UV_SHUTDOWN);
req->handle = stream;
// Callback executed after closing req->cb = cb;
stream->shutdown_req = req;
// Set the flag being closed stream->flags |= UV_HANDLE_SHUTTING;
// Register to wait for writable events uv__io_start(stream->loop, &stream->io_watcher, POLLOUT);
return 0;
}
Closing the write side of the stream is equivalent to sending a close request to the stream, mounting the request to the stream, and then registering to wait for a writable event, and the closing operation will be performed when the writable event is triggered. In the chapter on analyzing the write stream, we mentioned that when a writable event is triggered, uvdrain will be executed to log out and wait for the writable event. In addition, uvdrain also does one thing, which is to close the write end of the stream. Let's look at the specific logic.
static void uv__drain(uv_stream_t* stream) {
uv_shutdown_t* req;
int err;
// Cancel waiting for writable events, because no data needs to be written uv__io_stop(stream->loop, &stream->io_watcher, POLLOUT);
uv__stream_osx_interrupt_select(stream);
// The close write end is set, but it has not been closed, then execute the close write end if ((stream->flags & UV_HANDLE_SHUTTING) &&
!(stream->flags & UV_HANDLE_CLOSING) &&
!(stream->flags & UV_HANDLE_SHUT)) {
req = stream->shutdown_req;
stream->shutdown_req = NULL;
// clear flags stream->flags &= ~UV_HANDLE_SHUTTING;
uv__req_unregister(stream->loop, req);
err = 0;
// close the write end if (shutdown(uv__stream_fd(stream), SHUT_WR))
err = UV__ERR(errno);
// mark closed write end if (err == 0)
stream->flags |= UV_HANDLE_SHUT;
// execute callback if (req->cb != NULL)
req->cb(req, err);
}
}
The write end of the stream can be closed by calling shutdown, for example, the write end of the TCP stream can be closed after sending data. But still readable.
5.6 close stream
void uv__stream_close(uv_stream_t* handle) {
unsigned int i;
uv__stream_queued_fds_t* queued_fds;
// Remove the IO watcher from the event loop and move out of the pending queue uv__io_close(handle->loop, &handle->io_watcher);
// stop reading uv_read_stop(handle);
// stop handle
uv__handle_stop(handle);
// unreadable, write handle->flags &= ~(UV_HANDLE_READABLE | UV_HANDLE_WRITABLE);
// Close the file descriptor of the non-standard stream if (handle->io_watcher.fd != -1) {
/*
Don't close stdio file descriptors.
Nothing good comes from it.
*/
if (handle->io_watcher.fd > STDERR_FILENO)
uv__close(handle->io_watcher.fd);
handle->io_watcher.fd = -1;
}
// Close the file descriptor corresponding to the communication socket if (handle->accepted_fd != -1) {
uv__close(handle->accepted_fd);
handle->accepted_fd = -1;
}
// Same as above, this is the file descriptor queued for processing if (handle->queued_fds != NULL) {
queued_fds = handle->queued_fds;
for (i = 0; i < queued_fds->offset; i++)
uv__close(queued_fds->fds[i]);
uv__free(handle->queued_fds);
handle->queued_fds = NULL;
}
}
Closing a stream is to unregister the stream registered in epoll and close the file descriptor it holds.
5.7 Connection flow
Connection flow is for TCP and Unix domains, so we first introduce some network programming related content, first of all, we must have a socket. Let's see how to create a new socket in Libuv.
int uv__socket(int domain, int type, int protocol) {
int sockfd;
int err;
// Create a new socket and set the non-blocking and LOEXEC flags sockfd = socket(domain, type | SOCK_NONBLOCK | SOCK_CLOEXEC, protocol);
// Do not trigger the SIGPIPE signal, for example, the peer end has been closed, and the local end executes the write #if defined(SO_NOSIGPIPE)
{
int on = 1;
setsockopt(sockfd, SOL_SOCKET, SO_NOSIGPIPE, &on, sizeof(on));
}
#endif
return sockfd;
}
In Libuv, the socket mode is non-blocking. uv_socket is the function to apply for socket in Libuv, but Libuv does not directly call this function, but encapsulates it.
/*
1 Get a new socket fd
2 Save the fd in the handle, and set the relevant settings according to the flag 3 Bind to the random address of the machine (if the flag is set)
*/
static int new_socket(uv_tcp_t* handle,
int domain,
unsigned long flags) {
struct sockaddr_storage saddr;
socklen_t slen;
int sockfd;
// get a socket
sockfd = uv__socket(domain, SOCK_STREAM, 0);
// Set options and save the socket's file descriptor to the IO observernew_socket(handle, domain, flags);
}
There are many logical branches of the maybe_new_socket function, mainly as follows 1 If the stream has not been associated with fd, apply for a new fd to be associated with the stream 2 If the stream has been associated with an fd.
If the stream is marked with a binding address, but an address has been bound by Libuv (Libuv will set the UV_HANDLE_BOUND flag, the user may also directly call the bind function to bind). You do not need to bind again, just update the flags.
If the stream is marked with a binding address, but an address has not been bound through Libuv, at this time, getsocketname is used to determine whether the user has bound an address through the bind function. If yes, there is no need to perform the binding operation again. Otherwise bind to an address randomly.
The logic of the above two functions is mainly to apply for a socket and bind an address to the socket. Let's take a look at the implementation of the connection flow.
int uv__tcp_connect(uv_connect_t* req,
uv_tcp_t* handle,
const struct sockaddr* addr,
unsigned int addrlen,
uv_connect_cb cb) {
int err;
int r;
// The connect has been initiated if (handle->connect_req != NULL)
return UV_EALREADY;
// Apply for a socket and bind an address, if not yet err = maybe_new_socket(handle, addr->sa_family,
UV_HANDLE_READABLE | UV_HANDLE_WRITABLE
if (err)
return err;
handle->delayed_error = 0;
do {
// clear the value of the global error variable errno = 0;
// Non-blocking three-way handshake r = connect(uv__stream_fd(handle), addr, addrlen);
} while (r == -1 && errno == EINTR);
if (r == -1 && errno != 0) {
// The three-way handshake has not been completed if (errno == EINPROGRESS)
; /* not an error */
else if (errno == ECONNREFUSED)
// The other party refuses to establish a connection and delays reporting an error handle->delayed_error = UV__ERR(errno);
else
// Directly report an error return UV__ERR(errno);
}
// Initialize a connection request and set some fields uv__req_init(handle->loop, req, UV_CONNECT);
req->cb = cb;
req->handle = (uv_stream_t*) handle;
QUEUE_INIT(&req->queue);
// Connection request handle->connect_req = req;
// Register to the Libuv watcher queue uv__io_start(handle->loop, &handle->io_watcher, POLLOUT);
// Connection error, insert pending queue tail if (handle->delayed_error)
uv__io_feed(handle->loop, &handle->io_watcher);
return 0;
}
-
The logic of the connection flow is roughly as follows: 1 Apply for a socket and bind an address.
-
According to the given server address, initiate a three-way handshake, non-blocking, it will return directly to continue execution, and will not wait until the three-way handshake is completed.
-
Mount a connect request to the stream.
-
Set the events of interest to the IO observer as writable. Then insert the IO observer into the IO observer queue of the event loop. When waiting for writability (complete the three-way handshake), the cb callback will be executed.
When a writable event is triggered, uv__stream_io will be executed. Let's take a look at the specific logic.
if (stream->connect_req) {
uv__stream_connect(stream);
return;
}
We continue to look at uv__stream_connect.
static void uv__stream_connect(uv_stream_t* stream) {
int error;
uv_connect_t* req = stream->connect_req;
socklen_t errorsize = sizeof(int);
// Connection error if (stream->delayed_error) {
error = stream->delayed_error;
stream->delayed_error = 0;
} else {
// Still need to judge whether there is an error getsockopt(uv__stream_fd(stream),
SOL_SOCKET,
SO_ERROR,
&error,
&errorsize);
error = UV__ERR(error);
}
// If the connection is not successful, return first and wait for the next writable event to trigger if (error == UV__ERR(EINPROGRESS))
return;
// clear stream->connect_req = NULL;
uv__req_unregister(stream->loop, req);
/*
If there is a connection error, the previously registered waiting writable queue will be cancelled.
If the connection is successful, if the queue to be written is empty, log out the event, and register when there is data to be written*/
if (error < 0 || QUEUE_EMPTY(&stream->write_queue)) {
uv__io_stop(stream->loop, &stream->io_watcher, POLLOUT);
}
// Execute the callback to notify the upper layer of the connection result if (req->cb)
req->cb(req, error);
if (uv__stream_fd(stream) == -1)
return;
// Connection failed, flush data to be written and execute callback for write request (if any)
if (error < 0) {
uv__stream_flush_write_queue(stream, UV_ECANCELED);
uv__write_callbacks(stream);
}
}
The logic of the connection flow is 1. Initiate a non-blocking connection 2. Register and wait for a writable event. 3. When the writable event is triggered, tell the caller the connection result. 4. If the connection is successful, the data of the write queue is sent. The callback (if any) for each write request.
5.8 Listening stream
Listening stream is for TCP or Unix domain, mainly to change a socket to listen state. and set some properties.
int uv_tcp_listen(uv_tcp_t* tcp, int backlog, uv_connection_cb cb) {
static int single_accept = -1;
unsigned longerr = uv__accept(uv__stream_fd(stream));
// error handling if (err < 0) {
/*
The fd corresponding to uv__stream_fd(stream) is non-blocking,
Returning this error means that there is no connection available to accept, return directly */
if (err == -EAGAIN || err == -EWOULDBLOCK)
return; /* Not an error. */
if (err == -ECONNABORTED)
continue;
// The number of open file descriptors of the process reaches the threshold to see if there is a spare if (err == -EMFILE || err == -ENFILE) {
err = uv__emfile_trick(loop, uv__stream_fd(stream));
if (err == -EAGAIN || err == -EWOULDBLOCK)
break;
}
// An error occurs, execute the callback stream->connection_cb(stream, err);
continue;
}
// Record the fd corresponding to the communication socket obtained
stream->accepted_fd = err;
// Execute upload callback stream->connection_cb(stream, 0);
/*
If stream->accepted_fd is -1, it means that accepted_fd has been consumed in the callback connection_cb. Otherwise, the read event of the fd in the epoll of the server will be cancelled first, and then registered after consumption, that is, the request will not be processed any more*/
if (stream->accepted_fd != -1) {
/*
The user hasn't yet accepted called uv_accept()
*/
uv__io_stop(loop, &stream->io_watcher, POLLIN);
return;
}
/*
It is a TCP type stream and only one connection is set to accpet at a time, then it is blocked regularly.
Accept after being woken up, otherwise accept all the time (if the user consumes accept_fd in the connect callback), timing blocking is used for multi-process competition to process connections*/
if (stream->type == UV_TCP &&
(stream->flags & UV_TCP_SINGLE_ACCEPT)) {
struct timespec timeout = { 0, 1 };
nanosleep(&timeout, NULL);
}
}
}
When we see a connection coming, Libuv will pick a node from the queue of completed connections and then execute the connection_cb callback. In the connection_cb callback, uv_accept needs to consume accpet_fd.
int uv_accept(uv_stream_t* server, uv_stream_t* client) {
int err;
switch (client->type) {
case UV_NAMED_PIPE:
case UV_TCP:
// save the file descriptor to the client
err = uv__stream_open(client,
server->accepted_fd,
UV_STREAM_READABLE
| UV_STREAM_WRITABLE);
if (err) {
uv__close(server->accepted_fd);
goto done;
}
break;
case UV_UDP:
err = uv_udp_open((uv_udp_t*) client,
server->accepted_fd);
if (err) {
uv__close(server->accepted_fd);
goto done;
}
break;
default:
return -EINVAL;
}
client->flags |= UV_HANDLE_BOUND;
done:
// If it is not empty, continue to put one in accpet_fd and wait for accept, which is used for file descriptor transfer if (server->queued_fds != NULL) {
uv__stream_queued_fds_t* queued_fds;
queued_fds = server->queued_fds;
// assign the first one to accept_fd
server->accepted_fd = queued_fds->fds[0];
/*
offset minus one unit, if there is no more, free the memory,
Otherwise, you need to move the next one forward, and the offset executes the last one */
if (--queued_fds->offset == 0) {
uv__free(queued_fds);
server->queued_fds = NULL;
} else {
memmove(queued_fds->fds,
queued_fds->fds + 1,
queued_fds->offset * sizeof(*queued_fds->fds));
}
} else {
// If there is no queued fd, then register to wait for readable events, wait for accept new fd
server->accepted_fd = -1;
if (err == 0)
uv__io_start(server->loop, &server->io_watcher, POLLIN);
}
return err;
}
The client is the stream used to communicate with the client, and accept is to save the accept_fd to the client, and the client can communicate with the peer through fd. After consuming accept_fd, if there are still pending fds, you need to add one to accept_fd (for Unix domain), and the others continue to be queued for processing. If there are no pending fds, register and wait for readable events and continue to process new connections.
5.9 Destroying a stream
When we no longer need a stream, we will first call uv_close to close the stream. Closing the stream just cancels the event and releases the file descriptor. After calling uv_close, the structure corresponding to the stream will be added. When it comes to the closing queue, in the closing phase, the operation of destroying the stream will be performed, such as discarding the data that has not been written yet, and executing the callback of the corresponding stream. Let's take a look at the function uv__stream_destroy that destroys the stream.
void If the mode of the stream is read continuously,
1 If only part is read (UV_STREAM_READ_PARTIAL is set),
and did not read to the end (UV_STREAM_READ_EOF is not set),
Then it is directly processed for the end of reading,
2 If only part of it is read, the above read callback executes the read end operation,
Then there is no need to process 3. If the read-only part is not set, and the read end operation has not been performed,
The read end operation cannot be performed, because although the peer end is closed, the previously transmitted data may not have been consumed. 4 If the read-only part is not set and the read end operation is performed, then there is no need to process it here*/
if ((events & POLLHUP) &&
(stream->flags & UV_STREAM_READING) &&
(stream->flags & UV_STREAM_READ_PARTIAL) &&
!(stream->flags & UV_STREAM_READ_EOF)) {
uv_buf_t buf = { NULL, 0 };
uv__stream_eof(stream, &buf);
}
if (uv__stream_fd(stream) == -1)
return; /* read_cb closed stream. */
// writable event trigger if (events & (POLLOUT | POLLERR | POLLHUP)) {
// write data uv__write(stream);
// Do post-processing after writing, release memory, execute callbacks, etc. uv__write_callbacks(stream);
// If the queue to be written is empty, log out and wait for the write event if (QUEUE_EMPTY(&stream->write_queue))
uv__drain(stream);
}
}
This chapter introduces the principles and implementation of some core modules of the C++ layer in Node.js, which are used by many modules in Node.js. Only by understanding the principles of these modules can you better understand how JS calls Libuv through the C++ layer in Node.js, and how it returns from Libuv.
6.1 BaseObject
BaseObject is the base class for most classes in the C++ layer.
class BaseObject : public MemoryRetainer {
public:
// …
private:
v8::Local WrappedObject() const override;
// Point to the encapsulated object v8::Global persistent_handle_;
Environment* env_;
};
The implementation of BaseObject is very complicated, and only some commonly used implementations are introduced here.
6.1.1 Constructor
// Store the object in persistent_handle_, and take it out through object() if necessary BaseObject::BaseObject(Environment* env,
v8::Local object)
: persistent_handle_(env->isolate(), object),
env_(env) {
// Store this in object object->SetAlignedPointerInInternalField(0, static_cast (this));
}
The constructor is used to save the relationship between objects (the object used by JS and the C++ layer object related to it, the object in the figure below is the object we usually create by using the C++ module in the JS layer, such as new TCP()).
We can see the usefulness later, and the relationship is shown in Figure 6-1.
6.1.2 Get the encapsulated object
v8::Local BaseObject::object() const {
return PersistentToLocal::Default(env()->isolate(),
persistent_handle_);
}
6.1.3 Get the saved BaseObject object from the object
// Take out the BaseObject object saved inside through obj BaseObject*
BaseObject::FromJSObject(v8::Local obj) {
return static_cast (obj->GetAlignedPointerFromInternalField(0));
}
template
T* BaseObject::FromJSObject(v8::Local object) {
return static_cast (FromJSObject(object));
}
6.1.4 Unpacking
// Take the corresponding BaseObject object template from obj
inline T* Unwrap(v8::Local obj) {
return BaseObject::FromJSObject (obj);
}
// Get the corresponding BaseObject object from obj, if it is empty, return the value of the third parameter (default value)
#define ASSIGN_OR_RETURN_UNWRAP(ptr, obj, ...) \
do { \
*ptr = static_cast ::type>( \
BaseObject::FromJSObject(obj)); \
if (*ptr == nullptr) \
return __VA_ARGS__; \
} while (0)
6.2 AsyncWrap
AsyncWrap implements the async_hook module, but here we only focus on its function of calling back JS.
inline v8::MaybeLocal AsyncWrap::MakeCallback(
const v8::Local symbol,
int argc,
v8::Local *argv) {
v8::Local cb_v;
// According to the property value represented by the string, get the value corresponding to the property from the object. is a function
if (!object()->Get(env()->context(), symbol).ToLocal(&cb_v))
return v8::MaybeLocal ();
// is a function
if (!cb_v->IsFunction()) {
return v8::MaybeLocal ();
}
// callback, see async_wrap.cc
return MakeCallback(cb_v.As (), argc, argv);
}
The above is just the entry function, let's look at the real implementation.
MaybeLocal AsyncWrap::MakeCallback(const Local cb,
int argc,
Local *argv) {
MaybeLocal ret = InternalMakeCallback(env(), object(), cb, argc, argv, context);
return ret;
}
Then take a look at InternalMakeCallback
MaybeLocal InternalMakeCallback(Environment* env,
Local recv,
const Local callback,
int argc,
Local argv[],
async_context asyncContext) {
// …omit other code // execute callback callback->Call(env->context(), recv, argc, argv);}
6.3 HandleWrap
HandleWrap is the encapsulation of Libuv uv_handle_t and the base class of many C++ classes.
class HandleWrap : public AsyncWrap {
public:
// Operate and judge handle state function, see Libuv
static void Close(const v8::FunctionCallbackInfo & args);
static void Ref(const v8::FunctionCallbackInfo & args);
static void Unref(const v8::FunctionCallbackInfo & args);
static void HasRef(const v8::FunctionCallbackInfo & args);
static inline bool IsAlive(const HandleWrap* wrap) {
return wrap != nullptr && wrap->state_ != kClosed;
}
static inline bool HasRef(const HandleWrap* wrap) {
return IsAlive(wrap) && uv_has_ref(wrap->GetHandle());
}
// Get the packaged handle
inline uv_handle_t* GetHandle() const { return handle_; }
// Close the handle, and execute the callback virtual void Close(
v8::Local close_callback =
v8::Local ());
static v8::Local GetConstructorTemplate(
Environment* env);
protected:
HandleWrap(Environment* env,
v8::Local object,
uv_handle_t* handle,
AsyncWrap::ProviderType provider);
virtual void OnClose() {}
// handle state inline bool IsHandleClosing() const {
return state_ == kClosing || state_ == kClosed;
}
private:
friend class Environment;
friend void GetActiveHandles(const v8::FunctionCallbackInfo &);
static void OnClose(uv_handle_t* handle);
// handle queue ListNode handle_wrap_queue_;
// handle state enum { kInitialized, kClosing, kClosed } state_;
// base class for all handles uv_handle_t* const handle_;
};
6.3.1 New handle and initialization
Local HandleWrap::GetConstructorTemplate(Environment* env) {
Local tmpl = env->handle_wrap_ctor_template();
if (tmpl.IsEmpty()) {
tmpl = env->NewFunctionTemplate(nullptr);
tmpl->SetClassName(FIXED_ONE_BYTE_STRING(env->isolate(),
"HandleWrap"));
tmpl->Inherit(AsyncWrap::GetConstructorTemplate(env));
env->SetProtoMethod(tmpl, "close", HandleWrap::Close);
env->SetProtoMethodNoSideEffect(tmpl,
"hasRef",
HandleWrap::HasRef);
env->SetProtoMethod(tmpl, "ref", HandleWrap::Ref);
env->SetProtoMethod(tmpl, "unref", HandleWrap::Unref);
env->set_handle_wrap_ctor_template(tmpl);
}
return tmpl;
}
/*
object is the object provided by the C++ layer for the JS layer handle is the specific handle type of the subclass, different modules are different*/
HandleWrap::HandleWrap(Environment* env,
Local object,
uv_handle_t* handle,
AsyncWrap::ProviderType provider)
: AsyncWrap(env, object, provider),
state_(kInitialized),
handle_(handle) {
// Save the relationship between Libuv handle and C++ object handle_->data = this;
HandleScope scope(env->isolate());
CHECK(env->has_run_bootstrapping_code());
// Insert handle queue env->handle_wrap_queue()->PushBack(this);
}
HandleWrap inherits the BaseObject class, and the relationship diagram after initialization is shown in Figure 6-2.
AsyncWrap::ProviderType provider);
inline ~ReqWrap() override;
inline void Dispatched();
inline void Reset();
T* req() { return &req_; }
inline void Cancel() final;
inline AsyncWrap* GetAsyncWrap() override;
static ReqWrap* from_req(T* req);
template
// call Libuv
inline int Dispatch(LibuvFunction fn, Args... args);
public:
typedef void (*callback_t)();
callback_t original_callback_ = nullptr;
protected:
T req_;
};
}
Let's take a look at the implementation of cpp template
ReqWrap ::ReqWrap(Environment\* env,
v8::Local object,
AsyncWrap::ProviderType provider)
: AsyncWrap(env, object, provider),
ReqWrapBase(env) {
// Initialize state Reset();
}
// Save the relationship template between libuv data structure and ReqWrap instance
void ReqWrap ::Dispatched() {
req_.data = this;
}
// reset field template
void ReqWrap ::Reset() {
original_callback_ = nullptr;
req_.data = nullptr;
}
// Find the address template of the owning object through the req member
ReqWrap * ReqWrap ::from_req(T* req) {
return ContainerOf(&ReqWrap ::req_, req);
}
// Cancel the request template in the thread pool
void ReqWrap ::Cancel() {
if (req_.data == this)
uv_cancel(reinterpret_cast (&req_));
}
template
AsyncWrap* ReqWrap ::GetAsyncWrap() {
return this;
}
// Call the Libuv function template
template
int ReqWrap ::Dispatch(LibuvFunction fn, Args... args) {
Dispatched();
int err = CallLibuvFunction ::Call(
// Libuv function fn,
env()->event_loop(),
req(),
MakeLibuvRequestCallback ::For(this, args)...);
if (err >= 0)
env()->IncreaseWaitingRequestCounter();
return err;
}
We see that ReqWrap abstracts the process of requesting Libuv, and the specifically designed data structure is implemented by subclasses. Let's look at the implementation of a subclass.
// When requesting Libuv, the data structure is uv_connect_t, which means a connection request class ConnectWrap : public ReqWrap {
public:
ConnectWrap(Environment* env,
v8::Local req_wrap_obj,
AsyncWrap::ProviderType provider);
};
6.5 How JS uses C++
The ability of JS to call C++ modules is provided by V8, and Node.js uses this ability. In this way, we only need to face JS, and leave the rest to Node.js. This article first talks about how to use V8 to implement JS to call C++, and then talk about how Node.js does it.
- JS calls C++ First, let's introduce two very core classes in V8, FunctionTemplate and ObjectTemplate. As the names suggest, these two classes define templates, just like the design drawings when building a house. Through the design drawings, we can build the corresponding house. V8 is also, if you define a template, you can create a corresponding instance through this template. These concepts are described below (for convenience, the following is pseudocode).
1.1 Define a function template
Local functionTemplate = v8::FunctionTemplate::New(isolate(), New);
// Define the name of the function functionTemplate->SetClassName('TCP')
First define a FunctionTemplate object. We see that the second parameter of FunctionTemplate is a function, and when we execute the function created by FunctionTemplate, v8 will execute the New function. Of course we can also not pass it on.
1.2 Define the prototype content of the function template The prototype is the function.prototype in JS.
If you understand the knowledge in JS, it is easy to understand the code in C++.
v8::Local t = v8::FunctionTemplate::New(isolate(), callback);
t->SetClassName('test');
// Define a property on prototype t->PrototypeTemplate()->Set('hello', 'world');
1.3 Define the content of the instance template corresponding to the function template An instance template is an ObjectTemplate object. It defines the properties of the return value when the function created by the function template is executed as new.
function A() {
this.a = 1;
this.b = 2;
}
new A();
The instance template is similar to the code in the A function in the above code. Let's see how it is defined in V8.
t->InstanceTemplate()->Set(key, val);
t->InstanceTemplate()->SetInternalFieldCount(1);
InstanceTemplate returns an ObjectTemplate object. The SetInternalFieldCount function is special and important. We know that an object is a piece of memory, and an object has its own memory layout. We know that in C++, when we define a class, we define the layout of the object. For example, we have the following definition.
class demo
{
private:
intconst int kConstructorOffset = TemplateInfo::kHeaderSize;
static const int kInternalFieldCountOffset = kConstructorOffset + kPointerSize;
static const int kSize = kInternalFieldCountOffset + kHeaderSize;
};
The memory layout is shown in Figure 6-5.

Coming back to the question of object templates, let's see what Set(key, val) does.
void Template::Set(v8::Handle name, v8::Handle value, v8::PropertyAttribute attribute) {
// ... i::Handle list(Utils::OpenHandle(this)->property_list());
NeanderArray array(list);
array.add(Utils::OpenHandle(*name));
array.add(Utils::OpenHandle(*value));
array.add(Utils::OpenHandle(*v8::Integer::New(attribute)));
}
The above code is roughly to append some content to a list. Let's see how this list comes from, that is, the implementation of the property_list function.
// Read the value of a property in the object
#define READ_FIELD(p, offset) (*reinterpret_cast (FIELD_ADDR(p, offset))
static Object* cast(Object* value) { return value; }
Object* TemplateInfo::property_list() { return Object::cast(READ_FIELD(this, kPropertyListOffset)); }
From the above code, we know that the internal layout is shown in Figure 6-6.
 Figure 6-6
Figure 6-6
According to the memory layout, we know that the value of property_list is the value pointed to by list. Therefore, the memory operated by Set(key, val) is not the memory of the object itself. The object uses a pointer to point to a piece of memory to store the value of Set(key, val). The SetInternalFieldCount function is different, it affects (expands) the memory of the object itself. Let's take a look at its implementation.
void ObjectTemplate::SetInternalFieldCount(int value) {
// The modification is the value of the memory corresponding to kInternalFieldCountOffset
Utils::OpenHandle(this)->set_internal_field_count(i::Smi::FromInt(value)); }
We see that the implementation of the SetInternalFieldCount function is very simple, which is to save a number in the memory of the object itself. Next we look at the use of this field. Its usefulness will be described in detail later.
handle Factory::CreateApiFunction( handle obj, bool is_global) { int internal_field_count = 0; if (!obj->instance_template()->IsUndefined()) {
// Get the instance template Handle of the function template
instance_template = Handle (ObjectTemplateInfo::cast(obj->instance_template()));
// Get the value of the internal_field_count field of the instance template (the one set by SetInternalFieldCount)
internal_field_count = Smi::cast(instance_template->internal_field_count())->value(); }
// Calculate the space required for the new object, if int instance_size = kPointerSize
* internal_field_count; if (is_global) { instance_size += JSGlobalObject::kSize; } else { instance_size += JSObject::kHeaderSize; }
InstanceType type = is_global ? JS_GLOBAL_OBJECT_TYPE : JS_OBJECT_TYPE;
// Create a new function object Handle
result = Factory::NewFunction(Factory::empty_symbol(), type, instance_size, code, true); }
We see that the meaning of the value of internal_field_count is to expand the memory of the object.
For example, an object itself has only n bytes. If the value of internal_field_count is defined as 1, the memory of the object will become n+internal_field_count * The number of bytes of a pointer .
The memory layout is shown in Figure 6-7.  Figure 6-7
Figure 6-7
1.4 Create a function Local through a function template functionTemplate = v8::FunctionTemplate::New(isolate(), New); global->Set('demo', functionTemplate ->GetFunction()); In this way, we can directly call the demo variable in JS, and then the corresponding function will be executed. This is how JS calls C++.
- How Node.js handles the problem of JS calling C++ Let's take the TCP module as an example.
TCPWrap(env, args.This(), provider);
const { TCP } = process.binding('tcp_wrap'); new TCP(...);
We follow the inheritance relationship of TCPWrap, all the way to HandleWrap
HandleWrap::HandleWrap(Environment* env,
Local object,
uv_handle_t* handle,
AsyncWrap::ProviderType provider)
: AsyncWrap(env, object, provider),
state_(kInitialized),
handle_(handle) {
// Save the relationship between Libuv handle and C++ object handle_->data = this;
HandleScope scope(env->isolate());
// Insert handle queue env->handle_wrap_queue()->PushBack(this);
}
HandleWrap first saves the relationship between the Libuv structure and the C++ object. Then we continue to analyze along AsyncWrap, AsyncWrap inherits BaseObject, we look directly at BaseObject.
// Store the object in persistent_handle_, and take it out through object() if necessary BaseObject::BaseObject(Environment* env, v8::Local object)
: persistent_handle_(env->isolate(), object), env_(env) {
// Store this in object object->SetAlignedPointerInInternalField(0, static_cast (this));
env->AddCleanupHook(DeleteMe, static_cast (this));
env->modify_base_object_count(1);
}
We look at SetAlignedPointerInInternalField.
void v8::Object::SetAlignedPointerInInternalField(int index, void* value) {
i::Handle obj = Utils::OpenHandle(this);
i::Handle ::cast(obj)->SetEmbedderField(
index, EncodeAlignedAsSmi(value, location));
}
void JSObject::SetEmbedderField(int index, Smi* value) {
// GetHeaderSize is the size of the fixed layout of the object, kPointerSize * index is the expanded memory size, find the corresponding position according to the index
int offset = GetHeaderSize() + (kPointerSize * index);
// Write the memory of the corresponding location, that is, save the corresponding content to the memory
WRITE_FIELD(this, offset, value);
}
After the SetAlignedPointerInInternalField function is expanded, what it does is to save a value into the memory of the V8 C++ object. What is the stored value? The input parameter object of BaseObject is the object created by the function template, and this is a TCPWrap object. So what the SetAlignedPointerInInternalField function does is to save a TCPWrap object to an object created by a function template, as shown in Figure 6-8.
 Figure 6-8
Figure 6-8
What's the use of this? We continue to analyze. At this time, the new TCP is executed. Let's look at the logic of executing the tcp.connect() function at this time.
// template
void TCPWrap::Connect(const FunctionCallbackInfo & args,
std::function uv_ip_addr) {
Environment* env = Environment::GetCurrent(args);
TCPWrap* wrap;
ASSIGN_OR_RETURN_UNWRAP(&wrap,
args.Holder(),
args.GetReturnValue().Set(UV_EBADF));
// Omit some irrelevant code args.GetReturnValue().Set(err);
}
We just have to look at the logic of the ASSIGN_OR_RETURN_UNWRAP macro. Among them, args.Holder() represents the owner of the Connect function. According to the previous analysis, we know that the owner is the object created by the function template defined by the Initialize function. This object holds a TCPWrap object. The main logic of ASSIGN_OR_RETURN_UNWRAP is to take out the TCPWrap object saved in the C++ object. Then you can use the handle of the TCPWrap object to request Libuv.
6.7 C++ layer calls Libuv
Just now we analyzed how the JS calls the C++ layer and how they are linked together, and then we look at how the C++ calls Libuv and the Libuv callback C++ layer is linked together. We continue to analyze the process through the connect function of the TCP module.
template
void TCPWrap::Connect(const FunctionCallbackInfo & args,
std::function uv_ip_addr) {
Environment* env = Environment::GetCurrent(args);
TCPWrap* wrap;
ASSIGN_OR_RETURN_UNWRAP(&wrap,
args.Holder(),
args.GetReturnValue().Set(UV_EBADF));
// The first parameter is the TCPConnectWrap object, see the net module Local req_wrap_obj = args[0].As ();
// The second is the ip address node::Utf8Value ip_address(env->isolate(), args[1]);
T addr;
// Set the port and IP to addr, the port information is in the context of uv_ip_addr int err = uv_ip_addr(*ip_address, &addr);
if (err == 0) {
ConnectWrap* req_wrap =
new ConnectWrap(env,
req_wrap_obj,
)
that is because a large number of template parameters are used. CallLibuvFunction is essentially a struct, which is similar to a class in C++. There is only one class function Call. In order to adapt to the calls of various types of functions in the Libuv layer, Node.js implements Three types of CallLibuvFunction are used, and a large number of template parameters are used. We only need to analyze one. We start the analysis based on the connect function of TCP. We first specify the template parameters of the Dispatch function.
T corresponds to the type of ReqWrap, and LibuvFunction corresponds to the function type of Libuv. Here is int uv_tcp_connect(uv_connect_t* req, ...), so it corresponds to the second case of LibuvFunction. Args is the first argument when executing Dispatch. remaining parameters. Below we concrete Dispatch.
int ReqWrap ::Dispatch(int(*)(uv_connect_t*, Args...), Args... args) {
req_.data = this;
int err = CallLibuvFunction ::Call(
fn,
env()->event_loop(),
req(),
MakeLibuvRequestCallback ::For(this, args)...);
return err;
}
Then we look at the implementation of MakeLibuvRequestCallback.
// Transparently pass parameters to Libuv
template
struct MakeLibuvRequestCallback {
static T For(ReqWrap * req_wrap, T v) {
static_assert(!is_callable ::value,
"MakeLibuvRequestCallback missed a callback");
return v;
}
};
template
struct MakeLibuvRequestCallback {
using F = void(*)(ReqT* req, Args... args);
// Libuv callback static void Wrapper(ReqT* req, Args... args) {
// Get the corresponding C++ object ReqWrap through the Libuv structure * req_wrap = ReqWrap ::from_req(req);
req_wrap->env()->DecreaseWaitingRequestCounter();
// Get the original callback and execute F original_callback = reinterpret_cast (req_wrap->original_callback_);
original_callback(req, args...);
}
static F For(ReqWrap * req_wrap, F v) {
// Save the original function CHECK_NULL(req_wrap->original_callback_);
req_wrap->original_callback_=
reinterpret_cast ::callback_t>(v);
// Return the wrapper function return Wrapper;
}
};
There are two cases for the implementation of MakeLibuvRequestCallback. The first of the template parameters is generally a ReqWrap subclass, and the second is generally a handle.
When the ReqWrap class is initialized, the number of ReqWrap instances will be recorded in the env, so as to know how many requests are being made Processed by Libuv, if the second parameter of the template parameter is a function, it means that ReqWrap is not used to request Libuv, and the second implementation is used to hijack the callback to record the number of requests being processed by Libuv (such as the implementation of GetAddrInfo). So here we are adapting the first implementation. Transparently transmit C++ layer parameters to Libuv. Let's look at Dispatch again
int ReqWrap ::Dispatch(int(*)(uv_connect_t*, Args...), Args... args) {
req_.data = this;
int err = CallLibuvFunction ::Call(
fn,
env()->event_loop(),
req(),
args...);
return err;
}
Expand further.
static int Call(int(*fn)(uv_connect_t*, Args...), uv_loop_t* loop, uv_connect_t* req, PassedArgs... args) {
return fn(req, args...);
}
Finally expand
static int Call(int(_fn)(uv_connect_t_, Args...), uv_loop_t* loop, uv_connect_t* req, PassedArgs... args) {
return fn(req, args...);
}
Call(
uv_tcp_connect,
env()->event_loop(),
req(),
&wrap->handle_,
AfterConnect
)
uv_tcp_connect(
env()->event_loop(),
req(),
&wrap->handle_,
AfterConnect
);
Then let's see what uv_tcp_connect does.
int uv_tcp_connect(uv_connect_t* req,
uv_tcp_t* handle,
const struct sockaddr* addr,
uv_connect_cb cb) {
// ...
return uv__tcp_connect(req, handle, addr, addrlen, cb);
}
int uv__tcp_connect(uv_connect_t* req,
uv_tcp_t* handle,
const struct sockaddr* addr,
unsigned int addrlen,
uv_connect_cb cb) {
int err;
int r;
// Associated req->handle = (uv_stream_t*)Interestingly, the listener will be notified when there is data to read on the stream or when an event occurs.
```cpp
class StreamResource {
public:
virtual ~StreamResource();
// register/unregister waiting for stream read event virtual int ReadStart() = 0;
virtual int ReadStop() = 0;
// close the stream virtual int DoShutdown(ShutdownWrap* req_wrap) = 0;
// write stream virtual int DoTryWrite(uv_buf_t** bufs, size_t* count);
virtual int DoWrite(WriteWrap* w,
uv_buf_t* bufs,
size_t count,
uv_stream_t* send_handle) = 0;
// ...ignore some // add or remove listeners to the stream void PushStreamListener(StreamListener* listener);
void RemoveStreamListener(StreamListener* listener);
protected:
uv_buf_t EmitAlloc(size_t suggested_size);
void EmitRead(ssize_t nread,
const uv_buf_t& buf = uv_buf_init(nullptr, 0));
// The listener of the stream, that is, the data consumer StreamListener* listener_ = nullptr;
uint64_t bytes_read_ = 0;
uint64_t bytes_written_ = 0;
friend class StreamListener;
};
StreamResource is a base class, one of which is an instance of the StreamListener class, which we will analyze later. Let's look at the implementation of StreamResource. 1 Add a listener
// add a listener
inline void StreamResource::PushStreamListener(StreamListener* listener) {
// header method listener->previous_listener_ = listener_;
listener->stream_ = this;
listener_ = listener;
}
We can register multiple listeners on a stream, and the stream's listener_ field maintains all the listener queues on the stream. The relationship diagram is shown in Figure 6-15.
 Figure 6-15
Figure 6-15
- delete the listener
inline void StreamResource::RemoveStreamListener(StreamListener* listener) {
StreamListener* previous;
StreamListener* current;
// Traverse the singly linked list for (current = listener_, previous = nullptr;
/* No loop condition because we want a crash if listener is not found */
; previous = current, current = current->previous_listener_) {
if (current == listener) {
// non-null means that the node to be deleted is not the first node if (previous != nullptr)
previous->previous_listener_ = current->previous_listener_;
else
// The first node is deleted, just update the head pointer listener_ = listener->previous_listener_;
break;
}
}
// Reset the deleted listener's field listener->stream_ = nullptr;
listener->previous_listener_ = nullptr;
- Apply for storage data
// Apply for a block of memory inline uv*buf_t
StreamResource::EmitAlloc(size_t suggested_size) {
DebugSealHandleScope handle_scope(v8::Isolate::GetCurrent());
return listener*->OnStreamAlloc(suggested_size);
}
StreamResource just defines the general logic of the operation stream, and the data storage and consumption are defined by the listener.
- Data can be read
inline void StreamResource::EmitRead(ssize*t nread, const uv_buf_t& buf) {
if (nread > 0)
// record the size in bytes of the data read from the stream bytes_read* += static*cast (nread);
listener*->OnStreamRead(nread, buf);
}
- Write callback
inline void StreamResource::EmitAfterWrite(WriteWrap\* w, int status) {
DebugSealHandleScope handle*scope(v8::Isolate::GetCurrent());
listener*->OnStreamAfterWrite(w, status);
}
- close stream callback
inline void StreamResource::EmitAfterShutdown(ShutdownWrap\* w, int status) {
DebugSealHandleScope handle*scope(v8::Isolate::GetCurrent());
listener*->OnStreamAfterShutdown(w, status);
}
7 stream destroy callback
inline StreamResource::~StreamResource() {
while (listener_ != nullptr) {
StreamListener* listener = listener_;
listener->OnStreamDestroy();
if (listener == listener_)
RemoveStreamListener(listener_);
}
}
After the stream is destroyed, the listener needs to be notified and the relationship is released.
6.8.2 StreamBase
StreamBase is a subclass of StreamResource and extends the functionality of StreamResource.
class StreamBasereq_wrap->Dispose();
}
const char* msg = Error();
if (msg != nullptr) {
req_wrap_obj->Set(
env->context(),
env->error_string(),
OneByteString(env->isolate(), msg)).Check();
ClearError();
}
return err;
}
- write
// Write Buffer, support sending file descriptor int StreamBase::WriteBuffer(const FunctionCallbackInfo & args) {
Environment\* env = Environment::GetCurrent(args);
Local req_wrap_obj = args[0].As ();
uv_buf_t buf;
// data content and length buf.base = Buffer::Data(args[1]);
buf.len = Buffer::Length(args[1]);
uv_stream_t* send_handle = nullptr;
// is an object and the stream supports sending file descriptors if (args[2]->IsObject() && IsIPCPipe()) {
Local send_handle_obj = args[2].As ();
HandleWrap* wrap;
// Get the C++ layer object pointed to by internalField from the object returned by js ASSIGN_OR_RETURN_UNWRAP(&wrap, send_handle_obj, UV_EINVAL);
// Get the handle of the Libuv layer
send_handle = reinterpret_cast (wrap->GetHandle());
// Reference LibuvStreamWrap instance to prevent it from being garbage
// collected before `AfterWrite` is called.
// Set to the JS layer request object req_wrap_obj->Set(env->context(),
env->handle_string(),
send_handle_obj).Check();
}
StreamWriteResult res = Write(&buf, 1, send_handle, req_wrap_obj);
SetWriteResult(res);
return res.err;
}
inline StreamWriteResult StreamBase::Write(
uv_buf_t* bufs,
size_t count,
uv_stream_t* send_handle,
v8::Local req_wrap_obj) {
Environment* env = stream_env();
int err;
size_t total_bytes = 0;
// Calculate the size of the data to be written for (size_t i = 0; i < count; ++i)
total_bytes += bufs[i].len;
// same as above bytes_written_ += total_bytes;
// Do you need to send a file descriptor, if not, write directly if (send_handle == nullptr) {
err = DoTryWrite(&bufs, &count);
if (err != 0 || count == 0) {
return StreamWriteResult { false, err, nullptr, total_bytes };
}
}
HandleScope handle_scope(env->isolate());
AsyncHooks::DefaultTriggerAsyncIdScope trigger_scope(GetAsyncWrap());
// Create a write request object for requesting Libuv WriteWrap* req_wrap = CreateWriteWrap(req_wrap_obj);
// Execute write, subclass implementation, different stream write operations are different err = DoWrite(req_wrap, bufs, count, send_handle);
const char* msg = Error();
if (msg != nullptr) {
req_wrap_obj->Set(env->context(),
env->error_string(),
OneByteString(env->isolate(), msg)).Check();
ClearError();
}
return StreamWriteResult { async, err, req_wrap, total_bytes };
}
- read
// Operation stream, start reading int StreamBase::ReadStartJS(const FunctionCallbackInfo & args) {
return ReadStart();
}
// Operation stream, stop reading int StreamBase::ReadStopJS(const FunctionCallbackInfo & args) {
return ReadStop();
}
// Trigger stream event, there is data to read MaybeLocal StreamBase::CallJSOnreadMethod(ssize_t nread,
Local ab,
size_t offset,
StreamBaseJSChecks checks) {
Environment* env = env_;
env->stream_base_state()[kReadBytesOrError] = nread;
env->stream_base_state()[kArrayBufferOffset] = offset;
Local argv[] = {
ab.IsEmpty() ? Undefined(env->isolate()).As () : ab.As ()
};
// GetAsyncWrap is implemented in the StreamBase subclass, get the StreamBase class object AsyncWrap* wrap = GetAsyncWrap();
//Set(UV_EINVAL);
args.GetReturnValue().Set(wrap->GetFD());
}
void StreamBase::GetBytesRead(const FunctionCallbackInfo & args) {
StreamBase* wrap = StreamBase::FromObject(args.This().As ());
if (wrap == nullptr) return args.GetReturnValue().Set(0);
// uint64_t -> double. 53bits is enough for all real cases.
args.GetReturnValue().Set(static_cast (wrap->bytes_read_));
}
6.8.3 LibuvStreamWrap
LibuvStreamWrap is a subclass of StreamBase. It implements the interface of the parent class and also expands the capabilities of the stream.
class LibuvStreamWrap : public HandleWrap, public StreamBase {
public:
static void Initialize(v8::Local target,
v8::Local unused,
v8::Local context,
void* priv);
int GetFD() override;
bool IsAlive() override;
bool IsClosing() override;
bool IsIPCPipe() override;
// JavaScript functions
int ReadStart() override;
int ReadStop() override;
// Resource implementation
int DoShutdown(ShutdownWrap* req_wrap) override;
int DoTryWrite(uv_buf_t** bufs, size_t* count) override;
int DoWrite(WriteWrap* w,
uv_buf_t* bufs,
size_t count,
uv_stream_t* send_handle) override;
inline uv_stream_t* stream() const {
return stream_;
}
// is it a Unix domain or a named pipe inline bool is_named_pipe() const {
return stream()->type == UV_NAMED_PIPE;
}
// Is it a Unix domain and supports passing file descriptors inline bool is_named_pipe_ipc() const {
return is_named_pipe() &&
reinterpret_cast (stream())->ipc != 0;
}
inline bool is_tcp() const {
return stream()->type == UV_TCP;
}
// Create object ShutdownWrap requesting Libuv* CreateShutdownWrap(v8::Local object) override;
WriteWrap* CreateWriteWrap(v8::Local object) override;
// Get the corresponding C++ object from the JS layer object static LibuvStreamWrap* From(Environment* env, v8::Local object);
protected:
LibuvStreamWrap(Environment* env,
v8::Local object,
uv_stream_t* stream,
AsyncWrap::ProviderType provider);
AsyncWrap* GetAsyncWrap() override;
static v8::Local GetConstructorTemplate(
Environment* env);
private:
static void GetWriteQueueSize(
const v8::FunctionCallbackInfo & info);
static void SetBlocking(const v8::FunctionCallbackInfo & args);
// Callbacks for libuv
void OnUvAlloc(size_t suggested_size, uv_buf_t* buf);
void OnUvRead(ssize_t nread, const uv_buf_t* buf);
static void AfterUvWrite(uv_write_t* req, int status);
static void AfterUvShutdown(uv_shutdown_t* req, int status);
uv_stream_t* const stream_;
};
- Initialize
LibuvStreamWrap::LibuvStreamWrap(Environment* env,
Local object,
uv_stream_t* stream,
AsyncWrap::ProviderType provider)
: HandleWrap(env,
object,
reinterpret*cast (stream),
provider),
StreamBase(env),
stream*(stream) {
StreamBase::AttachToObject(object);
}
When LibuvStreamWrap is initialized, it will point the internal pointer of the object used by the JS layer to itself, see HandleWrap. 2 write operation
// Tool function to get the size of data bytes to be written void LibuvStreamWrap::GetWriteQueueSize(
const FunctionCallbackInfo & info) {
LibuvStreamWrap* wrap;
ASSIGN_OR_RETURN_UNWRAP(&wrap, info.This());
uint32_t write_queue_size =ggested_size, buf);
}, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) {
static_cast (stream->data)->OnUvRead(nread, buf);
});
}
// Implement stop reading logic int LibuvStreamWrap::ReadStop() {
return uv_read_stop(stream());
}
// The callback when memory needs to be allocated is called back by Libuv, and the specific memory allocation logic is implemented by the listener void LibuvStreamWrap::OnUvAlloc(size_t suggested_size, uv_buf_t* buf) {
HandleScope scope(env()->isolate());
Context::Scope context_scope(env()->context());
*buf = EmitAlloc(suggested_size);
}
// Process the passed file descriptor template
static MaybeLocal AcceptHandle(Environment* env,
LibuvStreamWrap* parent) {
EscapableHandleScope scope(env->isolate());
Local wrap_obj;
// Create an object representing the client according to the type, then save the file descriptor in it if (!WrapType::Instantiate(env, parent, WrapType::SOCKET).ToLocal(&wrap_obj))
return Local ();
// Solve the C++ layer object HandleWrap* wrap = Unwrap (wrap_obj);
CHECK_NOT_NULL(wrap);
// Get the handle encapsulated in the C++ object
uv_stream_t* stream = reinterpret_cast (wrap->GetHandle());
// Take a fd from the server stream and save it to steam
if (uv_accept(parent->stream(), stream))
ABORT();
return scope.Escape(wrap_obj);
}
// Implement OnUvRead, Libuv will call back when there is data in the stream or read to the end
void LibuvStreamWrap::OnUvRead(ssize_t nread, const uv_buf_t* buf) {
HandleScope scope(env()->isolate());
Context::Scope context_scope(env()->context());
uv_handle_type type = UV_UNKNOWN_HANDLE;
// Whether it supports passing file descriptors and there is a pending file descriptor, then determine the file descriptor type
if (is_named_pipe_ipc() &&
uv_pipe_pending_count(reinterpret_cast (stream())) > 0) {
type = uv_pipe_pending_type(reinterpret_cast (stream()));
}
// read successfully
if (nread > 0) {
MaybeLocal pending_obj;
// Create a new C++ object representing the client according to the type, and take a fd from the server and save it to the client
if (type == UV_TCP) {
pending_obj = AcceptHandle (env(), this);
} else if (type == UV_NAMED_PIPE) {
pending_obj = AcceptHandle (env(), this);
} else if (type == UV_UDP) {
pending_obj = AcceptHandle (env(), this);
} else {
CHECK_EQ(type, UV_UNKNOWN_HANDLE);
}
// If there is a file descriptor that needs to be processed, it is set to the JS layer object, and the JS layer uses
if (!pending_obj.IsEmpty()) {
object()
->Set(env()->context(),
env()->pending_handle_string(),
pending_obj.ToLocalChecked())
.Check();
}
}
// Trigger read event, listener implements
EmitRead(nread, *buf);
}
The read operation supports not only reading general data, but also reading file descriptors. The C++ layer will create a new stream object to represent the file descriptor. It can be used in the JS layer.
6.8.4 ConnectionWrap
ConnectionWrap is a subclass of LibuvStreamWrap that extends the connection interface. Applies to streams with connection attributes, such as Unix domains and TCP.
// WrapType is the class of the C++ layer, UVType is the type template of Libuv
class ConnectionWrap : public LibuvStreamWrap {
public:
static void OnConnection(uv_stream_t* handle, int status);
static void AfterConnect(uv_connect_t* req, int status);
protected:
ConnectionWrap(Environment* env,
v8::Local object,
ProviderType provider);
UVType handle_;
};
1 Callback after the connection is initiated
void ConnectionWrap ::AfterConnect(uv_connect_t* req,
int status) {
// Get the corresponding C++ object std::unique_ptr through the Libuv structure r
eq_wrap = (static_cast (req->data));
WrapType* wrap = static_cast (req->handle->data);
Environment\* env = wrap->env();
HandleScope handle_scope(env->isolate());
context())
.ToLocalChecked();
Local type_value = Int32::New(env->isolate(), type);
// Equivalent to the object we get when we call new TCP() in the JS layer return handle_scope.EscapeMaybe(
constructor->NewInstance(env->context(), 1, &type_value));
}
6.8.5 StreamReq
StreamReq represents a request to operate a stream. It mainly saves the request context and the general logic after the operation ends.
// Request Libuv's base class class StreamReq {
public:
// The internalField[1] of the object passed in by the JS layer saves the StreamReq class object static constexpr int kStreamReqField = 1;
// stream is the stream to be operated, req_wrap_obj is the object passed in by the JS layer explicit StreamReq(StreamBase* stream,
v8::Local req_wrap_obj) : stream_(stream) {
// JS layer object points to the current StreamReq object AttachToObject(req_wrap_obj);
}
// Subclass defines virtual AsyncWrap* GetAsyncWrap() = 0;
// Get the associated raw js object v8::Local object();
// The callback after the end of the request will execute the onDone of the subclass, which is implemented by the subclass
void Done(int status, const char* error_str = nullptr);
// The JS layer object no longer executes the StreamReq instance void Dispose();
// Get the stream being operated inline StreamBase* stream() const { return stream_; }
// Get the StreamReq object from the JS layer object static StreamReq* FromObject(v8::Local req_wrap_obj);
// Request all internalFields of JS layer objects to point to static inline void ResetObject(v8::Local req_wrap_obj);
protected:
// Callback virtual void OnDone(int status) = 0 after the request ends;
void AttachToObject(v8::Local req_wrap_obj);
private:
StreamBase* const stream_;
};
StreamReq has a member stream_, which represents the stream operated in the StreamReq request. Let's look at the implementation below. 1 JS layer request context and StreamReq relationship management.
inline void StreamReq::AttachToObject(v8::Local req_wrap_obj) {
req_wrap_obj->SetAlignedPointerInInternalField(kStreamReqField, this);
}
inline StreamReq* StreamReq::FromObject(v8::Local req_wrap_obj) {
return static_cast (
req_wrap_obj->GetAlignedPointerFromInternalField(kStreamReqField));
}
inline void StreamReq::Dispose() {
object()->SetAlignedPointerInInternalField(kStreamReqField, nullptr);
delete this;
}
inline void StreamReq::ResetObject(v8::Local obj) {
obj->SetAlignedPointerInInternalField(0, nullptr); // BaseObject field.
obj->SetAlignedPointerInInternalField(StreamReq::kStreamReqField, nullptr);
}
2 Get the original JS layer request object
// Get the original js object inline v8::Local associated with the request StreamReq::object() {
return GetAsyncWrap()->object();
}
3 Request end callback
inline void StreamReq::Done(int status, const char* error_str) {
AsyncWrap* async_wrap = GetAsyncWrap();
Environment\* env = async_wrap->env();
if (error_str != nullptr) {
async_wrap->object()->Set(env->context(),
env->error_string(),
OneByteString(env->isolate(),
error_str))
.Check();
}
// Execute the subclass's OnDone
OnDone(status);
}
After the stream operation request ends, Done will be executed uniformly, and Done will execute the OnDone function implemented by the subclass.
6.8.6 ShutdownWrap
ShutdownWrap is a subclass of StreamReq and represents a request to close the stream once.
class ShutdownWrap : public StreamReq {
public:
ShutdownWrap(StreamBase* stream,
v8::Local req_wrap_obj)
: StreamReq(stream, req_wrap_obj) { }
void OnDone(int status) override;
};
ShutdownWrap implements the OnDone interface and is executed by the base class after closing the stream.
/*
Callback at the end of the shutdown, Libuv is called by the request class (ShutdownWrap),
Therefore, after the Libuv operation is completed, the callback of the request class is executed first, the request class notifies the stream, the stream triggers the corresponding event, and further informs the listener
*/
inline void ShutdownWrap::OnDone(int status) {
stream()->EmitAfterShutdown(this, status);
Dispose();
}
6.8.7 Processing logic when the current stream is closed
inline void StreamListener::OnStreamAfterShutdown(ShutdownWrap* w, int status) {
previous_listener_->OnStreamAfterShutdown(w, status);
}
// Implement the processing logic at the end of writing inline void StreamListener::OnStreamAfterWrite(WriteWrap* w, int status) {
previous_listener_->OnStreamAfterWrite(w, status);
}
The logic of StreamListener is not much, and the specific implementation is in the subclass.
6.8.11 ReportWritesToJSStreamListener
ReportWritesToJSStreamListener is a subclass of StreamListener. Covers some interfaces and expands some functions.
class ReportWritesToJSStreamListener : public StreamListener {
public:
// Implement these two interfaces of the parent class void OnStreamAfterWrite(WriteWrap* w, int status) override;
void OnStreamAfterShutdown(ShutdownWrap* w, int status) override;
private:
void OnStreamAfterReqFinished(StreamReq* req_wrap, int status);
};
1 OnStreamAfterReqFinished OnStreamAfterReqFinished is a unified callback after the request operation stream ends.
void ReportWritesToJSStreamListener::OnStreamAfterWrite(
WriteWrap* req_wrap, int status) {
OnStreamAfterReqFinished(req_wrap, status);
}
void ReportWritesToJSStreamListener::OnStreamAfterShutdown(
ShutdownWrap* req_wrap, int status) {
OnStreamAfterReqFinished(req_wrap, status);
}
Let's take a look at the specific implementation
void ReportWritesToJSStreamListener::OnStreamAfterReqFinished(
StreamReq* req_wrap, int status) {
// Request the stream to operate on StreamBase* stream = static*cast (stream*);
Environment* env = stream->stream_env();
AsyncWrap* async_wrap = req_wrap->GetAsyncWrap();
HandleScope handle_scope(env->isolate());
Context::Scope context_scope(env->context());
// Get the original JS layer object Local req_wrap_obj = async_wrap->object();
Local argv[] = {
Integer::New(env->isolate(), status),
stream->GetObject(),
Undefined(env->isolate())
};
const char* msg = stream->Error();
if (msg != nullptr) {
argv[2] = OneByteString(env->isolate(), msg);
stream->ClearError();
}
// Callback JS layer if (req_wrap_obj->Has(env->context(), env->oncomplete_string()).FromJust())
async_wrap->MakeCallback(env->oncomplete_string(), arraysize(argv), argv);
}
OnStreamAfterReqFinished will call back the JS layer.
6.8.12 EmitToJSStreamListener
EmitToJSStreamListener is a subclass of ReportWritesToJSStreamListener
class EmitToJSStreamListener : public ReportWritesToJSStreamListener {
public:
uv_buf_t OnStreamAlloc(size_t suggested_size) override;
void OnStreamRead(ssize_t nread, const uv_buf_t& buf) override;
};
Let's take a look at the implementation
// Allocate a block of memory uv*buf_t
EmitToJSStreamListener::OnStreamAlloc(size_t suggested_size) {
Environment \* env = static_cast (stream*)->stream*env();
return env->AllocateManaged(suggested_size).release();
}
// Callback after reading data
void EmitToJSStreamListener::OnStreamRead(ssize_t nread, const uv_buf_t& buf*) {
StreamBase* stream = static*cast (stream*);
Environment* env = stream->stream*env();
HandleScope handle_scope(env->isolate());
Context::Scope context_scope(env->context());
AllocatedBuffer buf(env, buf*);
// read failed
if (nread <= 0) {
if (nread < 0)
stream->CallJSOnreadMethod(nread, Local ());
return;
}
buf.Resize(nread);
// read success callback JS layer stream->CallJSOnreadMethod(nread, buf.ToArrayBuffer());
}
We see that the listener will call back the interface of the stream after processing the data, and the specific logic is implemented by the subclass. Let's look at the implementation of a subclass (stream's default listener).
class EmitToJSStreamListener : public ReportWritesToJSStreamListener {
public:
uv_buf_t OnStreamAlloc(size_t suggested_size) override;
void OnStreamRead(ssize_t nread, const uv_buf_t& buf) override;
};
= static*cast (stream*);
Environment\* env = stream->stream*env();
HandleScope handle_scope(env->isolate());
Context::Scope context_scope(env->context());
AllocatedBuffer buf(env, buf*);
stream->CallJSOnreadMethod(nread, buf.ToArrayBuffer());
}
Continue to call back CallJSOnreadMethod
MaybeLocal StreamBase::CallJSOnreadMethod(ssize_t nread,
Local ab,
size_t offset,
StreamBaseJSChecks checks) {
Environment* env = env_;
// ...
AsyncWrap* wrap = GetAsyncWrap();
CHECK_NOT_NULL(wrap);
Local onread = wrap->object()->GetInternalField(kOnReadFunctionField);
CHECK(onread->IsFunction());
return wrap->MakeCallback(onread.As (), arraysize(argv), argv);
}
CallJSOnreadMethod will call back the onread callback function of the JS layer. onread will push the data to the stream, and then trigger the data event.